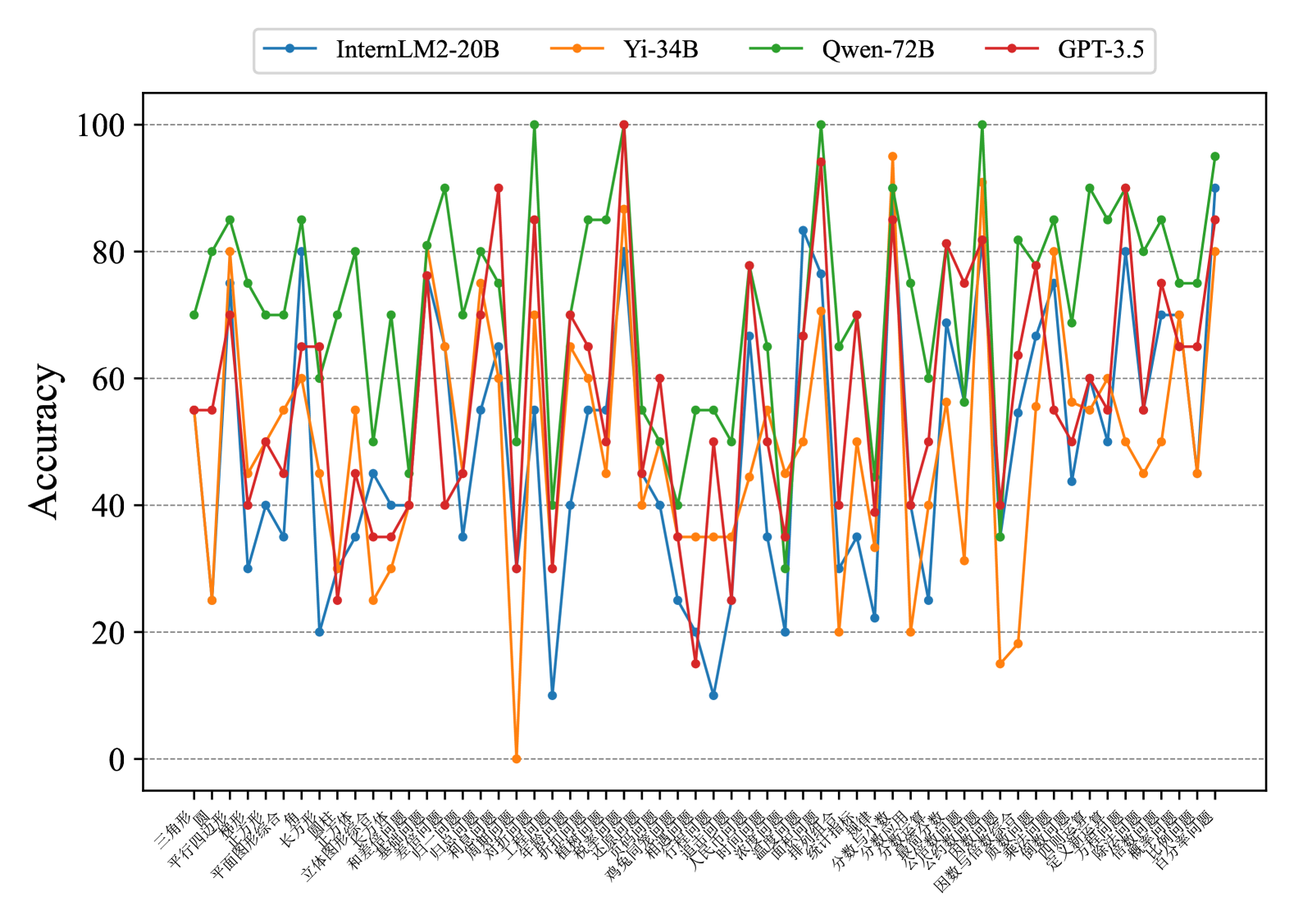
## Line Graph: Model Accuracy Comparison Across Tasks
### Overview
The image is a multi-line graph comparing the accuracy performance of four AI models (InternLM2-20B, Yi-34B, Qwen-72B, GPT-3.5) across 40+ Chinese-named tasks. The y-axis shows accuracy percentages (0-100), while the x-axis lists tasks in Chinese characters. The graph shows significant variability in performance across different tasks and models.
### Components/Axes
- **Legend**: Top-left corner with color-coded labels:
- Blue: InternLM2-20B
- Orange: Yi-34B
- Green: Qwen-72B
- Red: GPT-3.5
- **Y-axis**: "Accuracy" (0-100 scale)
- **X-axis**: Tasks labeled in Chinese (e.g., 三角形, 四边形, 立体图形, 机器学习)
- **Data Points**: Discrete markers connected by lines for each model
### Detailed Analysis
Key task-specific accuracy observations (approximate values with uncertainty):
1. **三角形 (Triangle)**:
- InternLM2-20B: ~75
- Yi-34B: ~80
- Qwen-72B: ~85
- GPT-3.5: ~55
2. **四边形 (Quadrilateral)**:
- InternLM2-20B: ~65
- Yi-34B: ~70
- Qwen-72B: ~75
- GPT-3.5: ~60
3. **立体图形 (3D Shapes)**:
- InternLM2-20B: ~80
- Yi-34B: ~75
- Qwen-72B: ~85
- GPT-3.5: ~65
4. **机器学习 (Machine Learning)**:
- InternLM2-20B: ~40
- Yi-34B: ~0 (data point missing)
- Qwen-72B: ~70
- GPT-3.5: ~40
5. **自然语言处理 (NLP)**:
- InternLM2-20B: ~60
- Yi-34B: ~55
- Qwen-72B: ~75
- GPT-3.5: ~65
*(Full task list available in original image)*
### Key Observations
1. **Qwen-72B Dominance**: Consistently highest accuracy across most tasks (e.g., 85-90% in 立体图形, 机器学习)
2. **Yi-34B Anomaly**: Near-zero accuracy in 机器学习 task (potential data error or model weakness)
3. **GPT-3.5 Variability**: Significant dips in performance for 机器学习 (~40) and 自然语言处理 (~65)
4. **InternLM2-20B**: Moderate performance with notable lows in 机器学习 (~40) and 自然语言处理 (~60)
5. **Task-Specific Performance**:
- Geometry tasks (三角形, 四边形) show highest overall accuracy
- 机器学习 task shows most model divergence
### Interpretation
The data suggests Qwen-72B demonstrates superior generalization across diverse tasks, particularly in computational and language processing domains. The Yi-34B's near-zero performance in 机器学习 (machine learning) task is particularly anomalous and warrants investigation - this could indicate either a data collection error or fundamental model limitations in this domain. GPT-3.5 shows consistent mid-range performance but lacks the peak capabilities of Qwen-72B. The InternLM2-20B model exhibits moderate performance with notable weaknesses in machine learning applications. These patterns highlight the importance of model selection based on specific task requirements, with Qwen-72B emerging as the most robust performer in this benchmark.