## Diagram: Language Model Translation Process with Long Context
### Overview
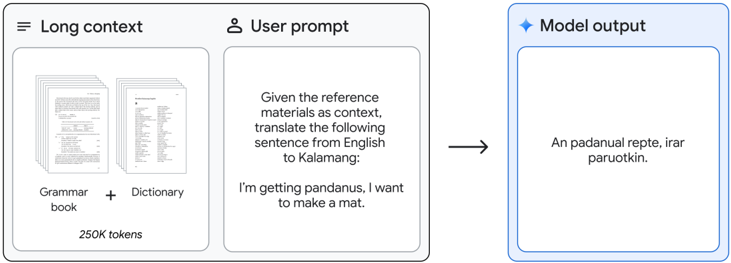
The image is a process diagram illustrating how a language model uses a large contextual reference to perform a translation task. It shows a three-stage flow: input of long-context documents, a user prompt, and the resulting model output. The diagram emphasizes the model's ability to utilize extensive reference materials (250K tokens) to translate a specific English sentence into the Kalamang language.
### Components/Axes
The diagram is divided into three main rectangular sections, connected by a right-pointing arrow indicating process flow.
1. **Left Section: "Long context"**
* **Header:** "Long context" with a hamburger menu icon (☰) to its left.
* **Content:** Two document icons are shown side-by-side.
* The left document is labeled **"Grammar book"**.
* The right document is labeled **"Dictionary"**.
* A plus sign (+) is positioned between them.
* **Footer:** The text **"250K tokens"** is centered below the document icons.
2. **Middle Section: "User prompt"**
* **Header:** "User prompt" with a user silhouette icon (👤) to its left.
* **Content:** A text box containing the following prompt:
* **Line 1:** "Given the reference materials as context, translate the following sentence from English to Kalamang:"
* **Line 2 (blank)**
* **Line 3:** "I'm getting pandanus, I want to make a mat."
3. **Right Section: "Model output"**
* **Header:** "Model output" with a four-pointed star icon (✦) to its left. This section has a light blue border, distinguishing it from the gray borders of the input sections.
* **Content:** A text box containing the model's generated translation:
* **Text:** "An padanual reptè, irar paruotkin."
4. **Flow Indicator:** A solid black arrow points from the right edge of the "User prompt" section to the left edge of the "Model output" section.
### Detailed Analysis
* **Process Flow:** The diagram depicts a linear sequence: `Long context (Reference Materials) + User prompt → Model processing → Model output (Translation)`.
* **Context Specification:** The "Long context" is explicitly defined as a combination of a "Grammar book" and a "Dictionary," with a quantified capacity of "250K tokens." This indicates the model's context window is filled with these reference materials.
* **Task Specification:** The user prompt is a direct instruction for translation. It specifies the source language (English), the target language (Kalamang), and provides the exact sentence to be translated: "I'm getting pandanus, I want to make a mat."
* **Output:** The model's output is a single line of text in the Kalamang language: "An padanual reptè, irar paruotkin." This is presented as the direct result of the translation task using the provided context.
### Key Observations
1. **Context-Driven Task:** The core function highlighted is **in-context learning** or **retrieval-augmented generation**. The model is not relying solely on its pre-trained parameters but is actively using provided reference documents (grammar and dictionary) to perform a specific, low-resource language task.
2. **Quantified Context:** The explicit mention of "250K tokens" underscores the technical capability of handling very large context windows, which is necessary to include comprehensive reference materials like a full grammar book and dictionary.
3. **Specificity of Output:** The output is presented as a direct, unannotated translation, suggesting the model successfully synthesized the reference materials to generate a plausible Kalamang sentence.
4. **Visual Hierarchy:** The "Model output" section is visually emphasized with a blue border, drawing attention to the result of the process.
### Interpretation
This diagram serves as a technical illustration of a **large language model (LLM) performing a specialized translation task for a low-resource language (Kalamang) by leveraging a massive in-context reference library.**
* **What it demonstrates:** It showcases a practical application of long-context models beyond simple conversation. The model acts as a **specialized tool** that can be "loaded" with domain-specific knowledge (here, linguistic rules and vocabulary) to execute precise tasks. This is more efficient and potentially more accurate than relying solely on the model's internal, possibly sparse, knowledge of Kalamang.
* **Relationship between elements:** The "Long context" is the foundational knowledge base. The "User prompt" is the specific query that activates and directs the application of that knowledge. The "Model output" is the synthesized result. The arrow signifies that the output is causally dependent on both the context and the prompt.
* **Underlying significance:** The diagram implicitly argues for the value of **massive context windows** in AI models. It suggests that with enough context (250K tokens), a model can be effectively "taught" or "equipped" on-the-fly to handle tasks in domains where its pre-trained knowledge is limited, such as translating between English and a less-documented language like Kalamang. The choice of a translation task involving "pandanus" (a plant used for weaving mats) hints at the model's potential to handle culturally specific content.