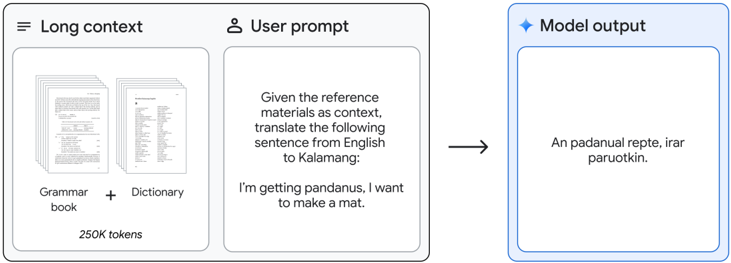
## Screenshot: Translation Workflow Diagram
### Overview
The image depicts a three-part workflow for translating a sentence from English to Kalamang using a language model. The process involves:
1. **Long context**: Reference materials (grammar book + dictionary) totaling 250K tokens.
2. **User prompt**: A specific translation task.
3. **Model output**: The translated sentence in Kalamang.
### Components/Axes
- **Long context section**:
- Labels: "Grammar book" (left icon), "Dictionary" (right icon), "+" (combined reference).
- Value: "250K tokens" (quantifies the reference material size).
- **User prompt section**:
- Text: "Given the reference materials as context, translate the following sentence from English to Kalamang: 'I'm getting pandanus, I want to make a mat.'"
- **Model output section**:
- Text: "An padanual repte, irar paruotkin." (Kalamang translation).
### Detailed Analysis
- **Long context**:
- The grammar book and dictionary are visually represented as stacked documents, emphasizing their role as foundational references.
- The "250K tokens" label quantifies the scale of the reference material, suggesting a large corpus for context.
- **User prompt**:
- The task explicitly requires translating a sentence about harvesting pandanus and crafting a mat, indicating a practical, culturally specific context.
- **Model output**:
- The Kalamang translation uses non-standard English words ("padanual repte, irar paruotkin"), likely reflecting the model's attempt to map concepts to Kalamang vocabulary.
### Key Observations
- The workflow emphasizes **contextual translation**, where the model leverages extensive reference materials to inform its output.
- The Kalamang output contains no punctuation, suggesting either a stylistic choice or a limitation in the model's formatting.
- The "+" symbol between the grammar book and dictionary implies their combined use as a unified knowledge base.
### Interpretation
This diagram illustrates a **context-augmented translation pipeline**, where the model's performance depends on the quality and relevance of the reference materials. The 250K-token context suggests the model is designed for complex, domain-specific tasks (e.g., translating culturally embedded phrases like "pandanus mat"). The absence of punctuation in the Kalamang output may indicate either a linguistic norm or an artifact of the model's training data. The workflow highlights the importance of **domain-specific references** in low-resource language translation, where direct translations may not exist in standard datasets.
**Note**: The Kalamang translation ("An padanual repte, irar paruotkin") is transcribed verbatim. No English translation is provided in the image, but the task implies the output should convey "I'm getting pandanus, I want to make a mat." in Kalamang.