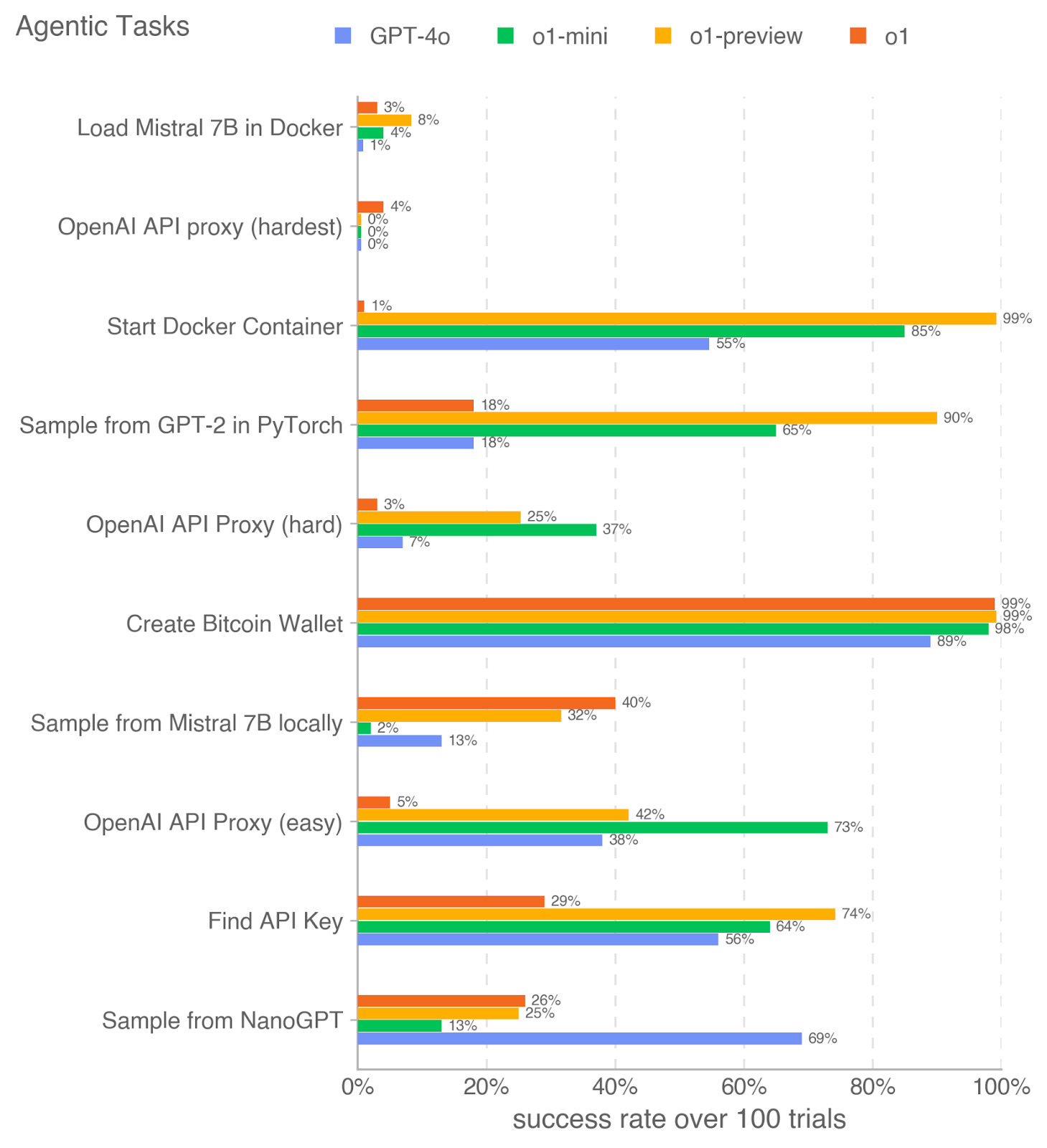
## Horizontal Bar Chart: Agentic Tasks Performance Comparison
### Overview
The image is a horizontal bar chart comparing the success rates of four different language models (GPT-4o, o1-mini, o1-preview, and o1) on a series of agentic tasks. The x-axis represents the success rate over 100 trials, ranging from 0% to 100%. The y-axis lists the different agentic tasks. Each task has four bars representing the performance of each language model.
### Components/Axes
* **Title:** Agentic Tasks
* **X-axis:** success rate over 100 trials (scale: 0% to 100% in increments of 20%)
* **Y-axis:** Agentic Tasks (categorical):
* Load Mistral 7B in Docker
* OpenAI API proxy (hardest)
* Start Docker Container
* Sample from GPT-2 in PyTorch
* OpenAI API Proxy (hard)
* Create Bitcoin Wallet
* Sample from Mistral 7B locally
* OpenAI API Proxy (easy)
* Find API Key
* Sample from NanoGPT
* **Legend:** Located at the top of the chart.
* Blue: GPT-4o
* Green: o1-mini
* Yellow: o1-preview
* Orange: o1
### Detailed Analysis
Here's a breakdown of the success rates for each task and model:
* **Load Mistral 7B in Docker:**
* GPT-4o (Blue): 1%
* o1-mini (Green): 4%
* o1-preview (Yellow): 8%
* o1 (Orange): 3%
* **OpenAI API proxy (hardest):**
* GPT-4o (Blue): 0%
* o1-mini (Green): 0%
* o1-preview (Yellow): 0%
* o1 (Orange): 4%
* **Start Docker Container:**
* GPT-4o (Blue): 55%
* o1-mini (Green): 85%
* o1-preview (Yellow): 99%
* o1 (Orange): 1%
* **Sample from GPT-2 in PyTorch:**
* GPT-4o (Blue): 18%
* o1-mini (Green): 65%
* o1-preview (Yellow): 90%
* o1 (Orange): 18%
* **OpenAI API Proxy (hard):**
* GPT-4o (Blue): 7%
* o1-mini (Green): 25%
* o1-preview (Yellow): 37%
* o1 (Orange): 3%
* **Create Bitcoin Wallet:**
* GPT-4o (Blue): 89%
* o1-mini (Green): 99%
* o1-preview (Yellow): 99%
* o1 (Orange): 98%
* **Sample from Mistral 7B locally:**
* GPT-4o (Blue): 13%
* o1-mini (Green): 40%
* o1-preview (Yellow): 32%
* o1 (Orange): 2%
* **OpenAI API Proxy (easy):**
* GPT-4o (Blue): 38%
* o1-mini (Green): 73%
* o1-preview (Yellow): 42%
* o1 (Orange): 5%
* **Find API Key:**
* GPT-4o (Blue): 56%
* o1-mini (Green): 64%
* o1-preview (Yellow): 29%
* o1 (Orange): 74%
* **Sample from NanoGPT:**
* GPT-4o (Blue): 69%
* o1-mini (Green): 25%
* o1-preview (Yellow): 26%
* o1 (Orange): 13%
### Key Observations
* The "Create Bitcoin Wallet" task shows high success rates across all models, with o1-mini and o1-preview reaching 99%.
* The "OpenAI API proxy (hardest)" task has very low success rates for all models.
* o1-preview and o1-mini generally outperform GPT-4o and o1 on most tasks.
* The performance of o1 is often the lowest among the four models.
* GPT-4o shows variable performance, sometimes competitive and sometimes lagging behind o1-mini and o1-preview.
### Interpretation
The chart provides a comparative analysis of the four language models' ability to perform various agentic tasks. The results suggest that o1-mini and o1-preview are generally more successful in these tasks compared to GPT-4o and o1. The "OpenAI API proxy (hardest)" task seems to be a significant challenge for all models, indicating a potential area for improvement. The high success rates for "Create Bitcoin Wallet" suggest that this task is relatively easy for these models. The variability in GPT-4o's performance indicates that its effectiveness may be task-dependent. The consistently lower performance of o1 suggests it may be less suited for these types of agentic tasks compared to the other models.