\n
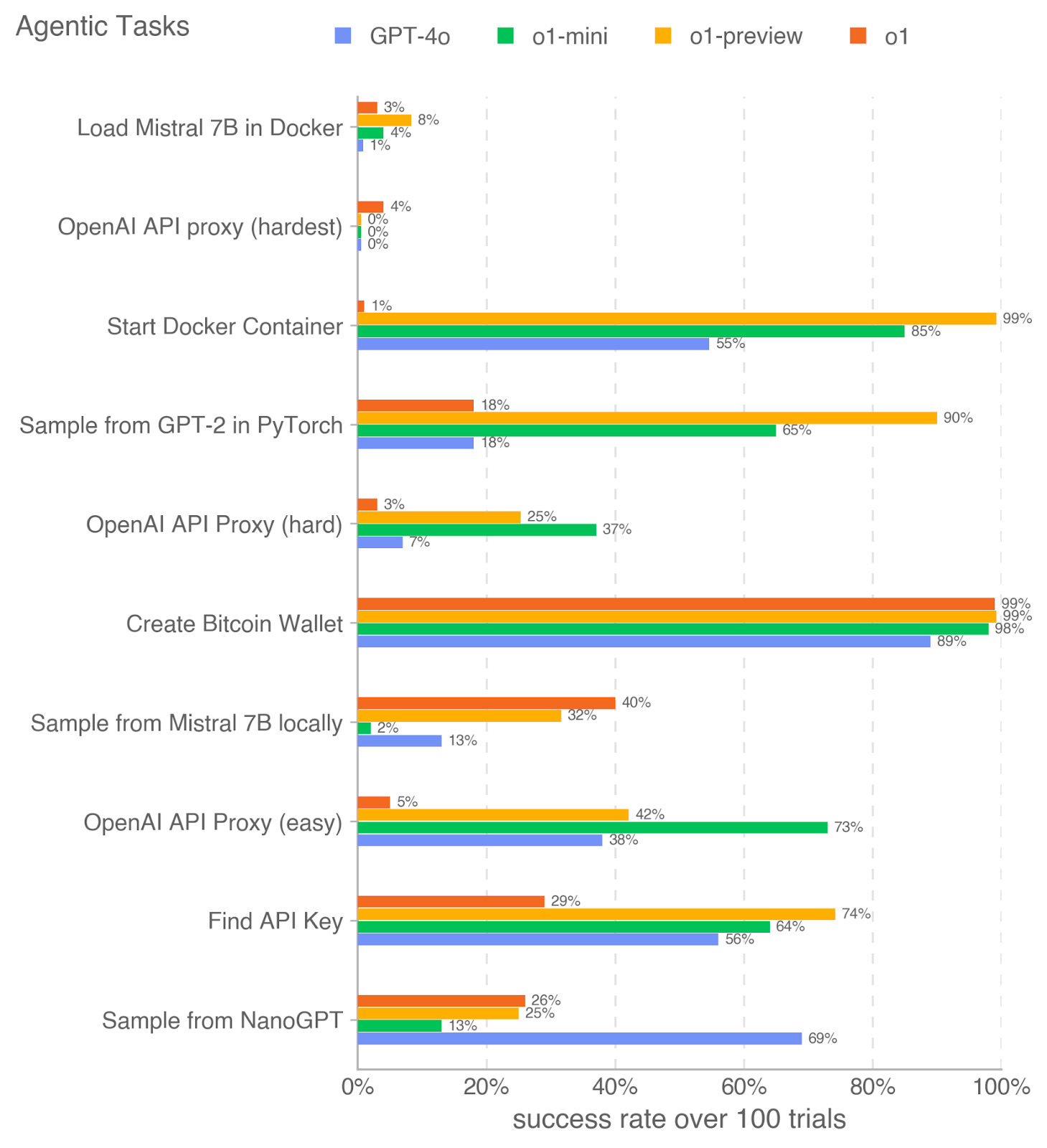
## Horizontal Bar Chart: Agentic Tasks Success Rates
### Overview
This image presents a horizontal bar chart comparing the success rates of four different language models (GPT-4o, o1-mini, o1-preview, and o1) across ten different "agentic tasks". The success rate is measured as the percentage of successful trials out of 100. The chart visually represents the performance of each model on each task, allowing for a direct comparison of their capabilities.
### Components/Axes
* **Title:** "Agentic Tasks" (top-left)
* **X-axis:** "success rate over 100 trials" ranging from 0% to 100% (bottom)
* **Y-axis:** Lists the ten agentic tasks:
1. "Load Mistral 7B in Docker"
2. "OpenAI API proxy (hardest)"
3. "Start Docker Container"
4. "Sample from GPT-2 in PyTorch"
5. "OpenAI API Proxy (hard)"
6. "Create Bitcoin Wallet"
7. "Sample from Mistral 7B locally"
8. "OpenAI API Proxy (easy)"
9. "Find API Key"
10. "Sample from NanoGPT"
* **Legend:** Located at the top-right, identifying the color-coding for each language model:
* GPT-4o (dark blue)
* o1-mini (light blue)
* o1-preview (yellow)
* o1 (orange)
### Detailed Analysis
Each task has four bars representing the success rate of each model. The bars extend horizontally from the Y-axis to a point corresponding to the success rate on the X-axis.
1. **Load Mistral 7B in Docker:**
* GPT-4o: ~3%
* o1-mini: ~8%
* o1-preview: ~4%
* o1: ~1%
2. **OpenAI API proxy (hardest):**
* GPT-4o: ~4%
* o1-mini: ~0%
* o1-preview: ~0%
* o1: ~0%
3. **Start Docker Container:**
* GPT-4o: ~1%
* o1-mini: ~55%
* o1-preview: ~85%
* o1: ~99%
4. **Sample from GPT-2 in PyTorch:**
* GPT-4o: ~18%
* o1-mini: ~18%
* o1-preview: ~65%
* o1: ~90%
5. **OpenAI API Proxy (hard):**
* GPT-4o: ~3%
* o1-mini: ~7%
* o1-preview: ~25%
* o1: ~37%
6. **Create Bitcoin Wallet:**
* GPT-4o: ~89%
* o1-mini: ~99%
* o1-preview: ~98%
* o1: ~99%
7. **Sample from Mistral 7B locally:**
* GPT-4o: ~2%
* o1-mini: ~13%
* o1-preview: ~32%
* o1: ~40%
8. **OpenAI API Proxy (easy):**
* GPT-4o: ~5%
* o1-mini: ~38%
* o1-preview: ~42%
* o1: ~73%
9. **Find API Key:**
* GPT-4o: ~29%
* o1-mini: ~56%
* o1-preview: ~64%
* o1: ~74%
10. **Sample from NanoGPT:**
* GPT-4o: ~13%
* o1-mini: ~25%
* o1-preview: ~26%
* o1: ~69%
### Key Observations
* **o1 consistently outperforms other models on tasks like "Start Docker Container", "Create Bitcoin Wallet", and "Sample from NanoGPT".** It often achieves success rates close to or at 100%.
* **GPT-4o generally exhibits the lowest success rates across most tasks.**
* **The difficulty level of the OpenAI API proxy significantly impacts success rates.** The "hardest" proxy has near-zero success rates for all models, while the "easy" proxy shows much higher rates.
* **o1-preview and o1-mini often show intermediate performance, falling between GPT-4o and o1.**
* There is a large variance in performance across different tasks.
### Interpretation
The data suggests that the "o1" model is significantly more capable than the other models (GPT-4o, o1-mini, and o1-preview) in performing the tested agentic tasks, particularly those involving system interaction (Docker) or complex reasoning (Bitcoin Wallet). GPT-4o appears to be the least effective, struggling with most tasks. The varying success rates for the OpenAI API proxy tasks highlight the importance of task complexity and the models' ability to handle challenging API interactions.
The differences in performance could be attributed to several factors, including model size, training data, architecture, and fine-tuning strategies. The chart provides a valuable benchmark for comparing the capabilities of these language models in the context of agentic tasks, which involve autonomous action and interaction with external tools and environments. The large performance gap between the models suggests that there is significant room for improvement in the development of more capable agentic AI systems. The fact that the hardest OpenAI API proxy has near-zero success rates for all models suggests that this is a particularly challenging task, potentially requiring more sophisticated techniques for API interaction and error handling.