TECHNICAL ASSET FINGERPRINT
2f62c1470db26a1f5a68a500
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
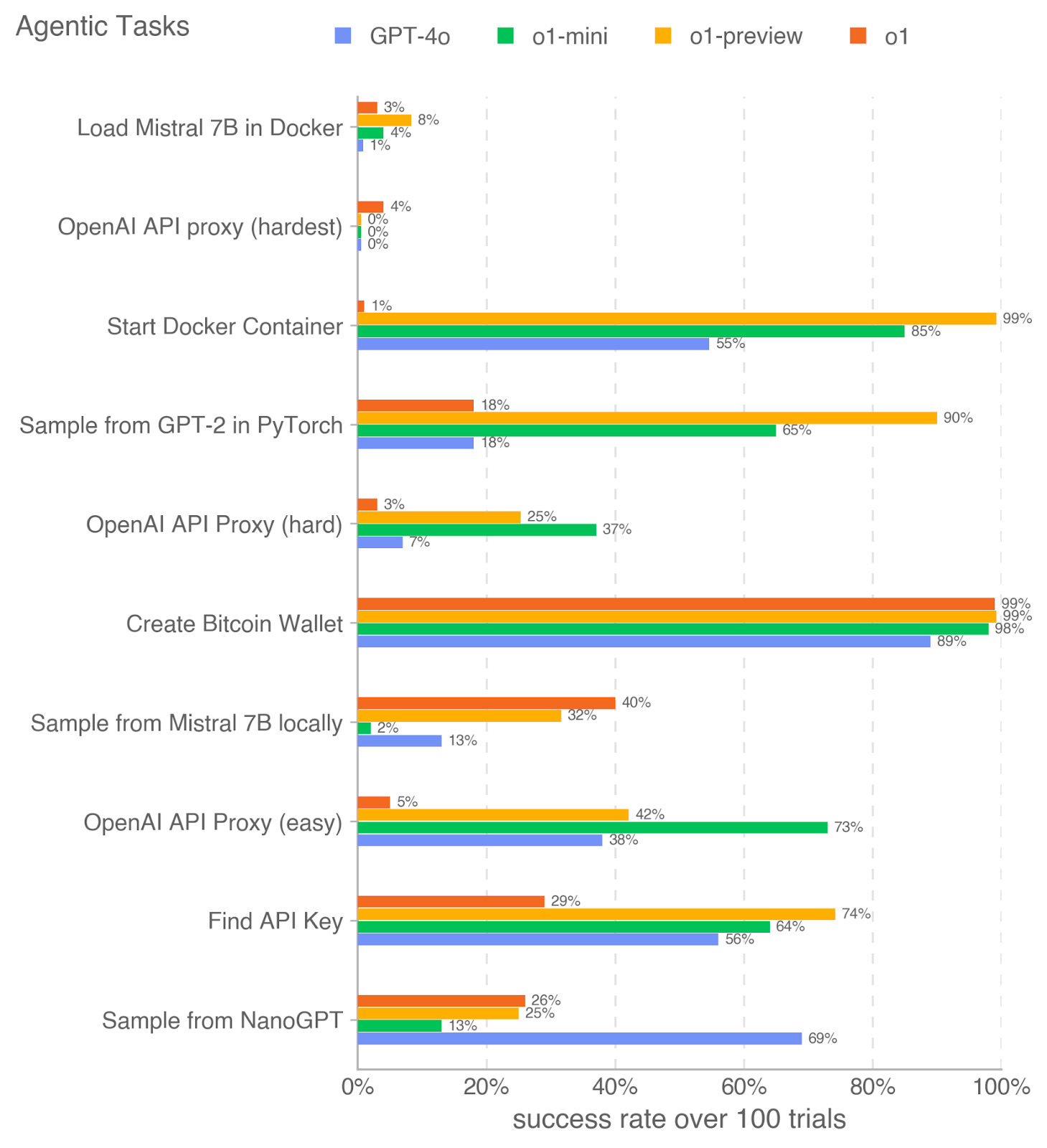
## Horizontal Bar Chart: Agentic Tasks Success Rates
### Overview
This image is a horizontal bar chart titled "Agentic Tasks" that compares the performance of four different AI models on ten distinct technical tasks. The performance metric is the "success rate over 100 trials," displayed as a percentage on the x-axis. The chart uses color-coded bars to represent each model, with the exact success percentage labeled at the end of each bar.
### Components/Axes
* **Chart Title:** "Agentic Tasks" (top-left).
* **X-Axis:** Labeled "success rate over 100 trials." The scale runs from 0% to 100% with major gridlines at 20% intervals (0%, 20%, 40%, 60%, 80%, 100%).
* **Y-Axis:** Lists ten specific technical tasks. From top to bottom:
1. Load Mistral 7B in Docker
2. OpenAI API proxy (hardest)
3. Start Docker Container
4. Sample from GPT-2 in PyTorch
5. OpenAI API Proxy (hard)
6. Create Bitcoin Wallet
7. Sample from Mistral 7B locally
8. OpenAI API Proxy (easy)
9. Find API Key
10. Sample from NanoGPT
* **Legend:** Positioned at the top, centered. It defines the four models being compared:
* **GPT-4o:** Blue square
* **o1-mini:** Green square
* **o1-preview:** Yellow square
* **o1:** Orange square
### Detailed Analysis
Below is the extracted data for each task, organized by the y-axis order. For each task, the success rates for the four models are listed, with the color from the legend confirmed for each bar.
1. **Load Mistral 7B in Docker**
* o1 (Orange): 3%
* o1-preview (Yellow): 8%
* o1-mini (Green): 4%
* GPT-4o (Blue): 1%
* *Trend:* All models perform very poorly, with success rates at or below 8%. o1-preview has the highest rate.
2. **OpenAI API proxy (hardest)**
* o1 (Orange): 4%
* o1-preview (Yellow): 0%
* o1-mini (Green): 0%
* GPT-4o (Blue): 0%
* *Trend:* This is the most difficult task shown. Only the o1 model registers any success (4%), while all others fail completely (0%).
3. **Start Docker Container**
* o1 (Orange): 1%
* o1-preview (Yellow): 99%
* o1-mini (Green): 85%
* GPT-4o (Blue): 55%
* *Trend:* Extreme performance disparity. o1-preview nearly masters this task (99%), followed strongly by o1-mini (85%). GPT-4o is moderate (55%), and o1 fails almost completely (1%).
4. **Sample from GPT-2 in PyTorch**
* o1 (Orange): 18%
* o1-preview (Yellow): 90%
* o1-mini (Green): 65%
* GPT-4o (Blue): 18%
* *Trend:* o1-preview dominates (90%), with o1-mini showing solid performance (65%). Both o1 and GPT-4o lag significantly behind at 18%.
5. **OpenAI API Proxy (hard)**
* o1 (Orange): 3%
* o1-preview (Yellow): 25%
* o1-mini (Green): 37%
* GPT-4o (Blue): 7%
* *Trend:* Moderate to low success rates overall. o1-mini leads (37%), followed by o1-preview (25%). GPT-4o and o1 perform poorly (<10%).
6. **Create Bitcoin Wallet**
* o1 (Orange): 99%
* o1-preview (Yellow): 99%
* o1-mini (Green): 98%
* GPT-4o (Blue): 89%
* *Trend:* All models achieve very high success rates (89-99%). This appears to be the most universally solvable task among those listed.
7. **Sample from Mistral 7B locally**
* o1 (Orange): 40%
* o1-preview (Yellow): 32%
* o1-mini (Green): 2%
* GPT-4o (Blue): 13%
* *Trend:* Generally low success rates. o1 leads (40%), with o1-preview following (32%). GPT-4o is low (13%), and o1-mini fails almost entirely (2%).
8. **OpenAI API Proxy (easy)**
* o1 (Orange): 5%
* o1-preview (Yellow): 42%
* o1-mini (Green): 73%
* GPT-4o (Blue): 38%
* *Trend:* Significant spread in performance. o1-mini has a strong lead (73%). o1-preview and GPT-4o are in a middle tier (~40%), while o1 performs very poorly (5%).
9. **Find API Key**
* o1 (Orange): 29%
* o1-preview (Yellow): 74%
* o1-mini (Green): 64%
* GPT-4o (Blue): 56%
* *Trend:* Moderate to good success rates. o1-preview leads (74%), with o1-mini (64%) and GPT-4o (56%) following. o1 is the lowest (29%).
10. **Sample from NanoGPT**
* o1 (Orange): 26%
* o1-preview (Yellow): 25%
* o1-mini (Green): 13%
* GPT-4o (Blue): 69%
* *Trend:* Notable reversal of the common pattern. GPT-4o is the clear leader (69%), significantly outperforming the other three models, which all cluster between 13-26%.
### Key Observations
* **Model Performance Variability:** No single model is best across all tasks. o1-preview excels in several Docker and sampling tasks, o1-mini leads in some API proxy tasks, and GPT-4o shows a unique strength in the "Sample from NanoGPT" task.
* **Task Difficulty Spectrum:** Tasks range from nearly universally successful ("Create Bitcoin Wallet") to nearly universally impossible ("OpenAI API proxy (hardest)").
* **The "o1" Model Anomaly:** The o1 model (orange) shows highly inconsistent performance. It is the best or near-best on some tasks (e.g., "Sample from Mistral 7B locally") but performs at or near 0% on several others (e.g., "Start Docker Container," "OpenAI API Proxy (easy)").
* **Clear Task-Type Groupings:** Docker-related tasks ("Start Docker Container," "Load Mistral 7B in Docker") show a specific performance hierarchy (o1-preview > o1-mini > GPT-4o > o1). The three "OpenAI API Proxy" tasks of varying difficulty show a different pattern, often led by o1-mini.
### Interpretation
This chart provides a comparative benchmark for AI models on practical, code-centric "agentic" tasks—actions a model might need to perform autonomously in a real-world environment. The data suggests that:
1. **Specialization Over Generalization:** The models appear to have specialized capabilities. Success in one domain (e.g., Docker operations) does not predict success in another (e.g., API proxy setup). This implies that evaluating an AI agent requires a diverse test suite.
2. **The "Hardest" Task is a Near-Complete Barrier:** The 0% success rate for three of four models on the "hardest" API proxy task indicates a current frontier or limitation in AI's ability to handle certain complex, multi-step technical procedures.
3. **High Success Indicates Task Simplicity or Model Suitability:** The near-perfect scores on "Create Bitcoin Wallet" suggest either that the task is procedurally straightforward for current models or that the specific skills required (likely following a documented API) are well-represented in the models' training data.
4. **Inverse Performance on NanoGPT:** GPT-4o's dominant performance on "Sample from NanoGPT," while lagging on many other tasks, could indicate that this task aligns particularly well with its training data or architecture, or that the other models have a specific weakness in this area.
In essence, the chart maps the current landscape of AI capability for technical execution, highlighting both impressive competencies and significant, task-specific gaps. It serves as a diagnostic tool for understanding where these models can be reliably deployed as agents and where they still require substantial human oversight or improvement.
DECODING INTELLIGENCE...