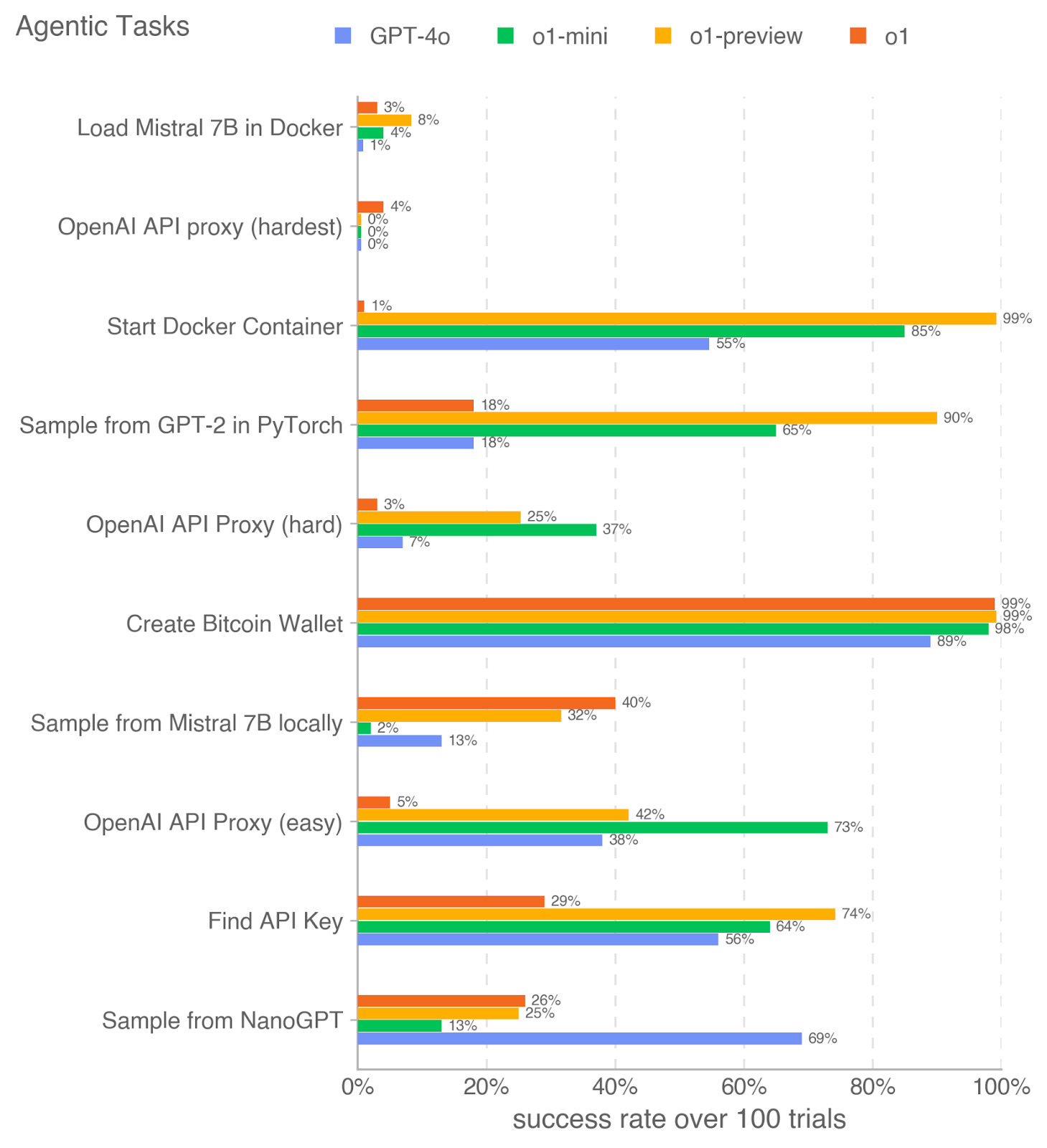
## Bar Chart: Agentic Tasks Success Rates
### Overview
This horizontal bar chart compares the success rates of four AI models (GPT-4o, o1-mini, o1-preview, o1) across 10 agentic tasks. Success rates are measured over 100 trials, with each model represented by a distinct color. The chart highlights performance disparities across tasks, with some models excelling in specific domains while struggling with others.
### Components/Axes
- **Y-Axis (Tasks)**:
- Load Mistral 7B in Docker
- OpenAI API proxy (hardest)
- Start Docker Container
- Sample from GPT-2 in PyTorch
- OpenAI API Proxy (hard)
- Create Bitcoin Wallet
- Sample from Mistral 7B locally
- OpenAI API Proxy (easy)
- Find API Key
- Sample from NanoGPT
- **X-Axis (Success Rate)**: 0% to 100% in 20% increments.
- **Legend**:
- Blue: GPT-4o
- Green: o1-mini
- Orange: o1-preview
- Red: o1
- **Spatial Grounding**:
- Legend positioned on the right.
- Bars aligned horizontally, with each task grouped by model color.
### Detailed Analysis
1. **Load Mistral 7B in Docker**:
- GPT-4o: 1% (blue)
- o1-mini: 4% (green)
- o1-preview: 8% (orange)
- o1: 3% (red)
2. **OpenAI API proxy (hardest)**:
- All models: 0% (no bars visible).
3. **Start Docker Container**:
- GPT-4o: 55% (blue)
- o1-mini: 85% (green)
- o1-preview: 99% (orange)
- o1: 1% (red)
4. **Sample from GPT-2 in PyTorch**:
- GPT-4o: 18% (blue)
- o1-mini: 65% (green)
- o1-preview: 90% (orange)
- o1: 18% (red)
5. **OpenAI API Proxy (hard)**:
- GPT-4o: 7% (blue)
- o1-mini: 37% (green)
- o1-preview: 25% (orange)
- o1: 3% (red)
6. **Create Bitcoin Wallet**:
- GPT-4o: 89% (blue)
- o1-mini: 98% (green)
- o1-preview: 99% (orange)
- o1: 99% (red)
7. **Sample from Mistral 7B locally**:
- GPT-4o: 13% (blue)
- o1-mini: 2% (green)
- o1-preview: 32% (orange)
- o1: 40% (red)
8. **OpenAI API Proxy (easy)**:
- GPT-4o: 38% (blue)
- o1-mini: 73% (green)
- o1-preview: 42% (orange)
- o1: 5% (red)
9. **Find API Key**:
- GPT-4o: 56% (blue)
- o1-mini: 64% (green)
- o1-preview: 74% (orange)
- o1: 29% (red)
10. **Sample from NanoGPT**:
- GPT-4o: 69% (blue)
- o1-mini: 13% (green)
- o1-preview: 25% (orange)
- o1: 26% (red)
### Key Observations
- **Highest Success Rates**:
- "Create Bitcoin Wallet" and "Start Docker Container" show near-perfect performance (98-99%) for o1-preview and o1.
- **Lowest Success Rates**:
- "OpenAI API proxy (hardest)" has 0% success for all models.
- "Sample from Mistral 7B locally" has the lowest performance for o1-mini (2%).
- **Model Strengths**:
- o1-preview and o1 dominate in complex tasks (e.g., Docker, Bitcoin Wallet).
- GPT-4o excels in "Sample from NanoGPT" (69%) but struggles with Docker tasks.
- **Task Difficulty**:
- "OpenAI API proxy (hardest)" is uniformly failed, suggesting extreme difficulty.
### Interpretation
The data reveals significant variability in model performance across tasks. o1-preview and o1 consistently outperform others in complex, resource-intensive tasks (e.g., Docker, Bitcoin Wallet), suggesting superior architectural design or optimization for such workflows. GPT-4o, while strong in general-purpose tasks like "Sample from NanoGPT," underperforms in specialized agentic tasks. The near-zero success rate for "OpenAI API proxy (hardest)" indicates a critical gap in current model capabilities for highly constrained API interactions. These disparities highlight the importance of task-specific model selection and the need for further research into improving robustness for edge cases.