TECHNICAL ASSET FINGERPRINT
2f6f1c5a2964b0df2454efd2
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
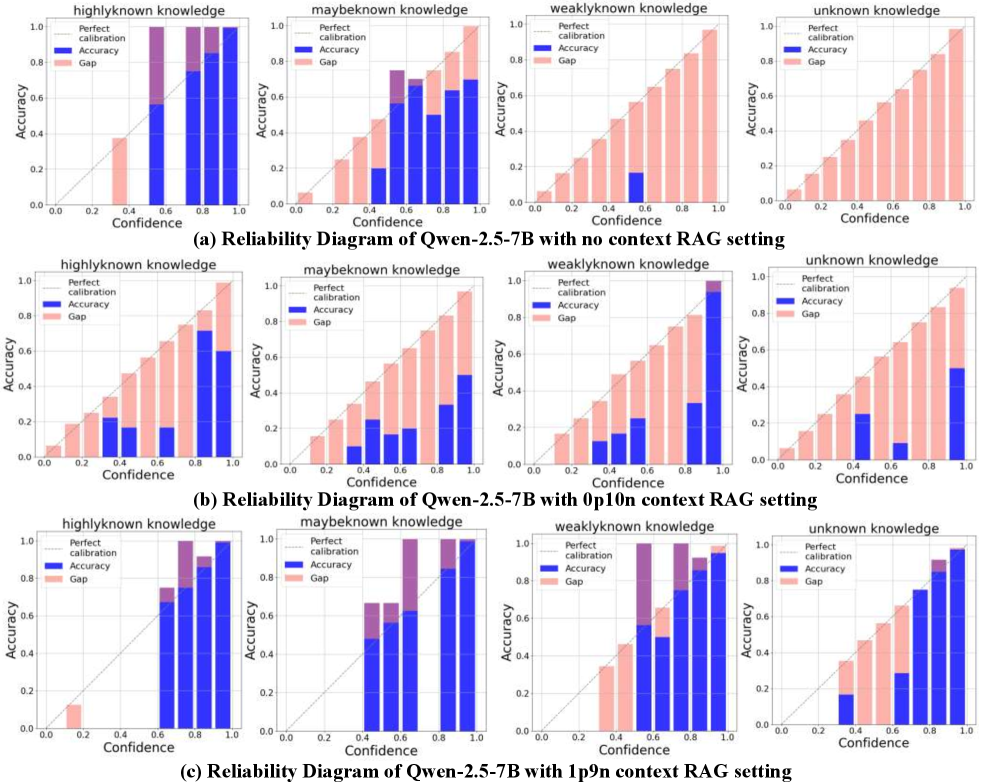
## Reliability Diagrams: Qwen-2.5-7B Calibration Across Knowledge Categories and RAG Settings
### Overview
The image displays a 3x4 grid of reliability diagrams (calibration plots) for the Qwen-2.5-7B language model. The diagrams evaluate the model's calibration—how well its confidence scores match its actual accuracy—across four knowledge categories and under three different Retrieval-Augmented Generation (RAG) context settings. Each row corresponds to a specific RAG setting, and each column corresponds to a specific knowledge category.
### Components/Axes
* **Overall Structure:** Three rows labeled (a), (b), and (c). Each row contains four subplots.
* **Subplot Titles (Columns):** From left to right: "highlyknown knowledge", "maybeknown knowledge", "weaklyknown knowledge", "unknown knowledge".
* **Axes (Identical for all subplots):**
* **X-axis:** "Confidence", scaled from 0.0 to 1.0 with increments of 0.2.
* **Y-axis:** "Accuracy", scaled from 0.0 to 1.0 with increments of 0.2.
* **Legend (Top-left of each subplot):**
* **Perfect calibration:** A gray diagonal line from (0,0) to (1,1). Represents ideal calibration where confidence equals accuracy.
* **Accuracy:** Blue bars. The height of each bar represents the model's actual accuracy for predictions within a specific confidence bin.
* **Gap:** Pink bars stacked on top of the blue bars. The total height (blue + pink) represents the model's confidence for that bin. The pink portion visualizes the miscalibration gap (Confidence - Accuracy).
* **Row Captions (Below each row):**
* (a) Reliability Diagram of Qwen-2.5-7B with no context RAG setting
* (b) Reliability Diagram of Qwen-2.5-7B with 0p10n context RAG setting
* (c) Reliability Diagram of Qwen-2.5-7B with 1p9n context RAG setting
### Detailed Analysis
#### Row (a): No Context RAG Setting
* **highlyknown knowledge:** Blue bars (Accuracy) are generally close to or slightly below the perfect calibration line. The pink gaps are small to moderate, indicating reasonable but slightly overconfident calibration.
* **maybeknown knowledge:** Blue bars are consistently and significantly below the perfect calibration line, especially at mid-to-high confidence (0.4-0.8). Large pink gaps indicate substantial overconfidence (confidence > accuracy).
* **weaklyknown knowledge:** Similar to "maybeknown," with blue bars far below the diagonal. Very large pink gaps across most confidence bins show severe overconfidence.
* **unknown knowledge:** Blue bars are extremely low, often near zero, across all confidence levels. The pink gaps are massive, filling almost the entire plot area. This indicates the model is highly overconfident when it lacks knowledge, assigning high confidence to almost entirely incorrect answers.
#### Row (b): 0p10n Context RAG Setting
* **highlyknown knowledge:** Calibration improves compared to (a). Blue bars are closer to the diagonal, with smaller pink gaps, especially at higher confidence levels.
* **maybeknown knowledge:** Improvement is visible. Blue bars are higher than in (a), reducing the pink gap, but a notable overconfidence gap remains, particularly in the 0.6-0.8 confidence range.
* **weaklyknown knowledge:** Shows some improvement over (a). Blue bars are higher, but large pink gaps persist, indicating continued significant overconfidence.
* **unknown knowledge:** Still shows severe miscalibration. While blue bars are slightly higher than in (a) at very high confidence (0.8-1.0), the pink gaps remain enormous, demonstrating the model is still highly overconfident about its unknowns.
#### Row (c): 1p9n Context RAG Setting
* **highlyknown knowledge:** Calibration appears very good. Blue bars closely follow the perfect calibration line with minimal pink gaps.
* **maybeknown knowledge:** Calibration is significantly improved. Blue bars are much closer to the diagonal, with small pink gaps, indicating well-calibrated confidence.
* **weaklyknown knowledge:** Shows the most dramatic improvement. Blue bars are now much higher and closer to the diagonal, though a moderate pink gap remains at the highest confidence bin (0.8-1.0).
* **unknown knowledge:** Improvement is evident but miscalibration persists. Blue bars are higher than in (a) and (b), especially at high confidence, but substantial pink gaps remain, showing the model is still overconfident, though less severely than with no context.
### Key Observations
1. **Knowledge Hierarchy:** Calibration consistently improves from "unknown" to "highlyknown" knowledge across all settings. The model is best calibrated on what it knows well and worst calibrated on what it doesn't know.
2. **RAG Impact:** The context setting has a profound effect on calibration.
* **No Context (a):** Worst calibration, especially severe overconfidence on "unknown" and "weaklyknown" knowledge.
* **0p10n Context (b):** Provides moderate improvement, reducing but not eliminating overconfidence.
* **1p9n Context (c):** Provides the best calibration, bringing "highlyknown" and "maybeknown" close to perfect calibration and significantly improving "weaklyknown."
3. **Persistent Overconfidence on Unknowns:** Even with the best context (1p9n), the model remains notably overconfident in the "unknown knowledge" category, as shown by the persistent pink gaps in the bottom-right subplot.
4. **Visual Trend:** The visual trend across rows (a) -> (b) -> (c) is a reduction in the size of the pink "Gap" bars and a rising of the blue "Accuracy" bars toward the diagonal "Perfect calibration" line, indicating improving calibration with better context.
### Interpretation
These reliability diagrams provide a diagnostic view of the Qwen-2.5-7B model's self-awareness. The data suggests:
1. **Intrinsic Overconfidence:** Without external context (Row a), the model exhibits a strong intrinsic bias toward overconfidence, particularly when operating at the edges of its knowledge ("weaklyknown", "unknown"). This is a common failure mode in LLMs.
2. **Context as a Calibration Tool:** Providing context through RAG acts as a powerful calibration mechanism. The "1p9n" setting (likely meaning 1 positive and 9 negative/irrelevant context passages) appears most effective. It likely helps the model better distinguish between what it knows and what it doesn't, grounding its confidence estimates in external evidence.
3. **Limits of Context:** The persistent gap in the "unknown knowledge" category, even with optimal context, indicates a fundamental challenge. The model may struggle to fully recognize or admit complete ignorance, even when provided with context that doesn't contain the answer. This has implications for reliability in high-stakes applications.
4. **Practical Implication:** For users of this model, the findings argue strongly for using a RAG system, specifically one configured like the "1p9n" setting, to obtain more trustworthy confidence scores. One should be especially skeptical of the model's high-confidence outputs when it is operating on poorly known or unknown topics, as the calibration gap remains significant in those areas.
**Language Declaration:** All text within the image is in English. No other languages are present.
DECODING INTELLIGENCE...