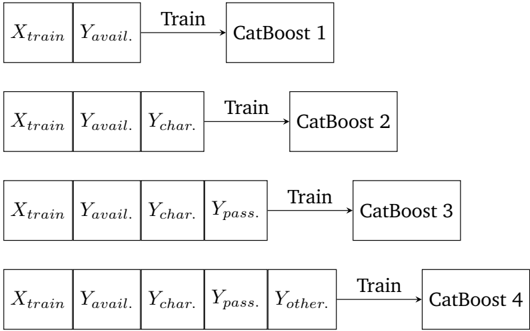
## Flowchart: CatBoost Model Training Pipeline
### Overview
The image depicts a sequential training pipeline for four CatBoost models, each incorporating progressively more input features. The flow moves left-to-right, with each stage adding new variables to the training process.
### Components/Axes
- **Input Variables**:
- `X_train` (constant across all stages)
- `Y_avail.` (constant across all stages)
- `Y_char.` (added in Stage 2)
- `Y_pass.` (added in Stage 3)
- `Y_other.` (added in Stage 4)
- **Output Models**:
- `CatBoost 1` (Stage 1)
- `CatBoost 2` (Stage 2)
- `CatBoost 3` (Stage 3)
- `CatBoost 4` (Stage 4)
- **Flow Direction**: Left-to-right progression, with each CatBoost model trained on the cumulative set of features from prior stages.
### Detailed Analysis
1. **Stage 1**:
- Inputs: `X_train`, `Y_avail.`
- Output: `CatBoost 1`
- Training arrow connects inputs to model.
2. **Stage 2**:
- Inputs: `X_train`, `Y_avail.`, `Y_char.`
- Output: `CatBoost 2`
- New feature `Y_char.` added to training data.
3. **Stage 3**:
- Inputs: `X_train`, `Y_avail.`, `Y_char.`, `Y_pass.`
- Output: `CatBoost 3`
- Additional feature `Y_pass.` included.
4. **Stage 4**:
- Inputs: `X_train`, `Y_avail.`, `Y_char.`, `Y_pass.`, `Y_other.`
- Output: `CatBoost 4`
- Final feature `Y_other.` incorporated.
### Key Observations
- **Feature Accumulation**: Each subsequent CatBoost model includes all previous features plus one new variable (`Y_char.`, `Y_pass.`, `Y_other.`).
- **No Numerical Data**: The diagram lacks quantitative values, focusing instead on architectural progression.
- **Sequential Dependency**: Later models explicitly depend on earlier training outputs, suggesting iterative refinement.
### Interpretation
This pipeline illustrates a **feature engineering strategy** where each CatBoost iteration builds on prior work by incorporating additional variables. The incremental addition of features (`Y_char.`, `Y_pass.`, `Y_other.`) implies an attempt to:
1. Capture more complex patterns in the data
2. Improve model performance through expanded feature sets
3. Test the impact of specific variables on predictive power
The absence of a legend or numerical metrics suggests this is a conceptual diagram rather than an empirical analysis. The left-to-right flow emphasizes **cumulative knowledge transfer** between models, with each CatBoost acting as both a consumer and producer in the pipeline. This pattern aligns with ensemble learning principles, where sequential model training can reduce bias and variance.