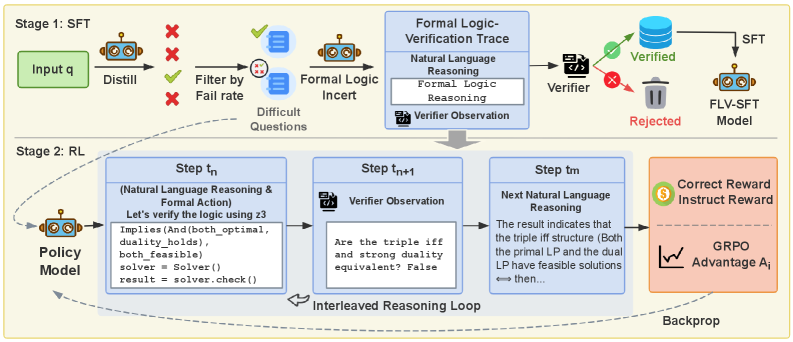
## Diagram: Formal Logic Verification with Reinforcement Learning
### Overview
The image is a diagram illustrating a two-stage process involving Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) for formal logic verification. The diagram outlines the flow of data and processes, including natural language reasoning, formal logic reasoning, and verification steps.
### Components/Axes
* **Stages:** The diagram is divided into two stages: Stage 1 (SFT) and Stage 2 (RL).
* **SFT Stage (Top):**
* **Input q:** A green rounded rectangle labeled "Input q" represents the initial input.
* **Distill:** An icon of a robot labeled "Distill" processes the input.
* **Filter by Fail rate:** A series of red "X" marks and a green checkmark indicate filtering based on a "Fail rate".
* **Difficult Questions:** A stack of documents labeled "Difficult Questions" represents the output of the filtering process.
* **Formal Logic Incert:** An icon of a robot labeled "Formal Logic Incert" processes the difficult questions.
* **Formal Logic-Verification Trace:** A blue box containing "Natural Language Reasoning", "Formal Logic Reasoning", and "Verifier Observation".
* **Verifier:** A code icon labeled "Verifier" checks the output.
* **Verified:** A green database icon labeled "Verified" represents successful verification.
* **Rejected:** A trash can icon labeled "Rejected" represents failed verification.
* **FLV-SFT Model:** An icon of a robot labeled "FLV-SFT Model" represents the final model.
* **RL Stage (Bottom):**
* **Policy Model:** An icon of a robot labeled "Policy Model" initiates the RL stage.
* **Step tn:** A blue box containing "(Natural Language Reasoning & Formal Action)" and code snippets. The code includes "Implies(And(both\_optimal, duality\_holds), both\_feasible)", "solver = Solver()", and "result = solver.check()".
* **Step tn+1:** A blue box containing "Verifier Observation" and the question "Are the triple iff and strong duality equivalent? False".
* **Step tm:** A blue box containing "Next Natural Language Reasoning" and the text "The result indicates that the triple iff structure (Both the primal LP and the dual LP have feasible solutions <-> then...".
* **Interleaved Reasoning Loop:** A curved arrow indicates a loop between the steps.
* **Correct Reward Instruct Reward:** A pink box containing a dollar sign icon and the text "Correct Reward Instruct Reward". Also contains a graph labeled "GRPO Advantage Ai".
* **Backprop:** An arrow labeled "Backprop" indicates the feedback loop.
### Detailed Analysis or ### Content Details
* **SFT Stage Flow:** The SFT stage begins with an input "q", which is distilled and then filtered based on a fail rate. The difficult questions are then processed by a formal logic component, verified, and either accepted or rejected.
* **RL Stage Flow:** The RL stage involves a policy model that interacts with the environment through a series of steps (tn, tn+1, tm). These steps involve natural language reasoning, formal action, and verifier observations. An interleaved reasoning loop connects these steps. The process is rewarded based on correctness, and the feedback is backpropagated to the policy model.
* **Code Snippets:** The code snippets in Step tn suggest the use of a solver to check logical implications and feasibility.
* **Questions:** The question in Step tn+1 indicates a check for equivalence between triple iff and strong duality.
### Key Observations
* The diagram illustrates a hybrid approach combining SFT and RL for formal logic verification.
* The process involves both natural language reasoning and formal logic reasoning.
* The RL stage uses an interleaved reasoning loop to refine the verification process.
### Interpretation
The diagram presents a system designed to improve formal logic verification through a combination of supervised learning and reinforcement learning. The SFT stage likely serves to pre-train a model on a dataset of logical problems, while the RL stage fine-tunes the model's reasoning and verification abilities through interaction with an environment. The interleaved reasoning loop in the RL stage suggests an iterative process of hypothesis generation and verification. The reward system encourages the model to produce correct and informative reasoning steps. The overall architecture aims to create a robust and reliable system for formal logic verification.