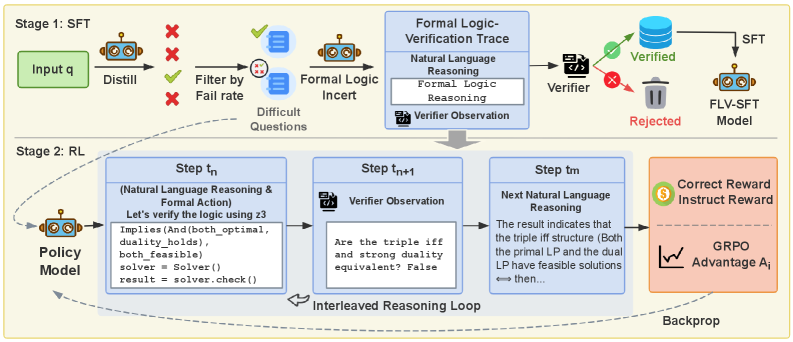
## Diagram: Formal Logic Verification Pipeline
### Overview
The image depicts a two-stage pipeline for training a model, combining Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) with a formal logic verification loop. The pipeline aims to improve model reliability by verifying reasoning steps using formal logic. The diagram illustrates the flow of data and control between different components, including input, distillation, filtering, formal logic insertion, verification, and policy updates.
### Components/Axes
The diagram is structured into two main stages: "Stage 1: SFT" and "Stage 2: RL". Within each stage, several components are interconnected. Key elements include:
* **Input q:** Represents the initial input query.
* **Distill:** A process that distills information from the input.
* **Filter by Fail rate:** A filtering mechanism based on failure rate.
* **Difficult Questions:** Questions that pose a challenge to the model.
* **Formal Logic Insert:** A component that inserts formal logic into the reasoning process.
* **Formal Logic Verification Trace:** A trace of the formal logic verification process, including Natural Language Reasoning and Formal Logic Reasoning.
* **Verifier:** A component that verifies the reasoning steps.
* **Verifier Observation:** The output of the verifier.
* **SFT:** Supervised Fine-Tuning stage.
* **FLV-SFT Model:** The resulting model after SFT with formal logic verification.
* **Policy Model:** The model used in the RL stage.
* **Step tn, tn+1, tm:** Represent iterative steps within the RL loop.
* **GRPO Advantage Ai:** Represents the advantage gained in the RL stage.
* **Backprop:** Backpropagation for policy updates.
* **Correct Reward/Instruct Reward:** The reward signal used in RL.
* **Interleaved Reasoning Loop:** The core loop of the RL stage.
### Detailed Analysis or Content Details
**Stage 1: SFT**
1. **Input q** is processed through **Distill**.
2. The distilled output is **Filtered by Fail rate**. Failed outputs (marked with a red 'X') are discarded.
3. Remaining outputs are passed to **Formal Logic Insert**.
4. The output of **Formal Logic Insert** is fed into the **Formal Logic Verification Trace**, which includes **Natural Language Reasoning** and **Formal Logic Reasoning**.
5. The **Verifier** evaluates the trace and produces a **Verifier Observation**.
6. If the verification is successful (green checkmark), the output is stored in **SFT**.
7. The verified data is used to train the **FLV-SFT Model**. If verification fails (red 'X'), the output is **Rejected**.
**Stage 2: RL**
1. The **Policy Model** receives input and generates an action.
2. **Step tn** shows an example of the reasoning process:
* **(Natural Language Reasoning & Formal Action):** "Let's verify the logic using z3. Implies (And(both_optimal, duality_holds), both_feasible) solver = Solver()"
* "result = solver.check()"
3. **Step tn+1** displays the **Verifier Observation**: "Are the triple iff and strong duality equivalent? False"
4. **Step tm** shows the **Next Natural Language Reasoning**: "The result indicates that the triple iff structure (Both the primal LP and the dual LP have feasible solutions then...)"
5. The **Correct Reward/Instruct Reward** is used to update the **Policy Model** via **Backprop**.
6. The **GRPO Advantage Ai** represents the improvement in the policy.
7. The entire process is encapsulated within an **Interleaved Reasoning Loop**.
### Key Observations
* The pipeline emphasizes the integration of formal logic verification into both SFT and RL stages.
* The RL stage involves an iterative loop where the policy model is refined based on verification results and rewards.
* The diagram highlights the importance of identifying and filtering out incorrect reasoning steps.
* The use of "z3" suggests a specific theorem prover is being employed for formal verification.
* The "Interleaved Reasoning Loop" suggests a tight coupling between reasoning, verification, and policy updates.
### Interpretation
This diagram illustrates a sophisticated approach to training language models that prioritizes correctness and reliability. By incorporating formal logic verification, the pipeline aims to mitigate the risk of generating incorrect or misleading outputs. The two-stage process – SFT followed by RL – allows for initial learning from supervised data and subsequent refinement through reinforcement learning guided by formal verification. The "Interleaved Reasoning Loop" is crucial, as it enables continuous feedback and improvement of the policy model. The use of a specific theorem prover (z3) indicates a commitment to rigorous verification. The diagram suggests a research effort focused on building more trustworthy and verifiable AI systems. The inclusion of "Difficult Questions" and "Fail rate" filtering suggests an attempt to focus training on challenging cases where errors are more likely to occur. The overall design reflects a desire to move beyond purely statistical learning and incorporate symbolic reasoning into the training process.