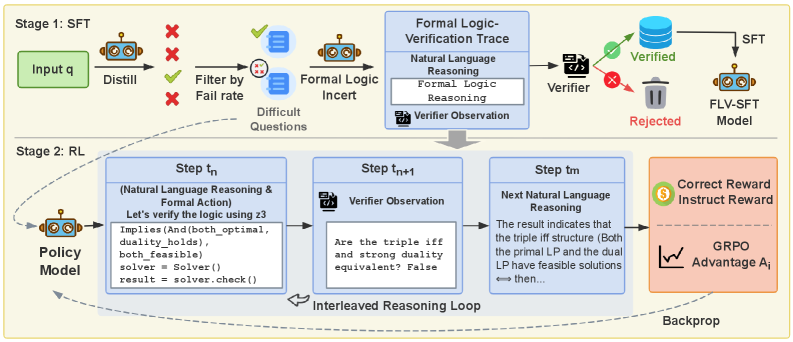
## Flowchart: Two-Stage SFT and RL Process with Formal Verification
### Overview
The diagram illustrates a two-stage technical process combining Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) with formal logic verification. It includes input distillation, filtering, verification loops, and reward optimization. Key components include policy models, verifiers, and GRPO (Generalized Reinforcement Policy Optimization) advantage calculations.
### Components/Axes
1. **Stage 1: SFT**
- Input box labeled "Input q" (green)
- Robot icon labeled "Distill" with red X (rejected) and green check (accepted)
- Filtering step labeled "Filter by Fail rate"
- Output: "Difficult Questions" with formal logic verification
- Verification components:
- "Formal Logic Verification Trace"
- "Natural Language Reasoning"
- "Formal Logic Reasoning" (code snippet)
- Verifier with green check (verified) and red X (rejected)
- Outputs: "Verified" (green) and "Rejected" (red) paths
- FLV-SFT Model (robot icon)
2. **Stage 2: RL**
- Interleaved Reasoning Loop:
- Step tn: "Natural Language Reasoning & Formal Action" with code snippet
- Step tn+1: "Verifier Observation" with question/answer
- Step tn: "Next Natural Language Reasoning"
- Policy Model (robot icon)
- Reward system:
- "Correct Reward"
- "Instruct Reward"
- GRPO Advantage A_i (graph icon)
3. **Legend**
- Green checkmark: Accepted/Verified
- Red X: Rejected/Failed
- Positioned in top-left corner
### Detailed Analysis
- **Stage 1 Flow**:
1. Input q → Distill (robot)
2. Filtering by fail rate → Difficult Questions
3. Formal verification:
- Natural Language Reasoning → Formal Logic Reasoning (code: `implies(And(both_optimal, duality_holds), both_feasible)`)
- Verifier checks equivalence (e.g., "Are the triple iff and strong duality equivalent? False")
4. Verified questions proceed to SFT; rejected go to FLV-SFT Model
- **Stage 2 Flow**:
1. Policy Model generates reasoning steps
2. Interleaved loop:
- Natural Language Reasoning + Formal Action (code execution)
- Verifier observation feedback
- Iterative refinement of reasoning
3. GRPO Advantage A_i calculation (graph icon) for reward optimization
### Key Observations
1. **Dual Verification**: Questions undergo both natural language and formal logic verification
2. **Iterative Refinement**: Stage 2 uses an explicit interleaved reasoning loop for continuous improvement
3. **Reward Structure**: Combines correct/instruct rewards with GRPO optimization
4. **Failure Handling**: Rejected questions in Stage 1 are reprocessed through FLV-SFT Model
5. **Code Integration**: Direct execution of formal logic (Z3 solver) within reasoning steps
### Interpretation
This diagram represents a hybrid AI training pipeline that:
1. **Filters low-quality inputs** through fail rate analysis before formal verification
2. **Combines symbolic reasoning** (Z3 solver) with natural language processing in an RL framework
3. **Optimizes rewards** using GRPO advantage calculations, suggesting a focus on policy gradient methods
4. **Emphasizes verification** at multiple stages, indicating safety-critical applications
5. **Uses visual metaphors** (robot icons, checkmarks) to represent automated processes
The architecture suggests a system designed for complex reasoning tasks requiring both linguistic understanding and formal verification, with continuous improvement through reinforcement learning. The GRPO component implies optimization of policy updates using advantage estimation, likely for more efficient learning than standard PPO.