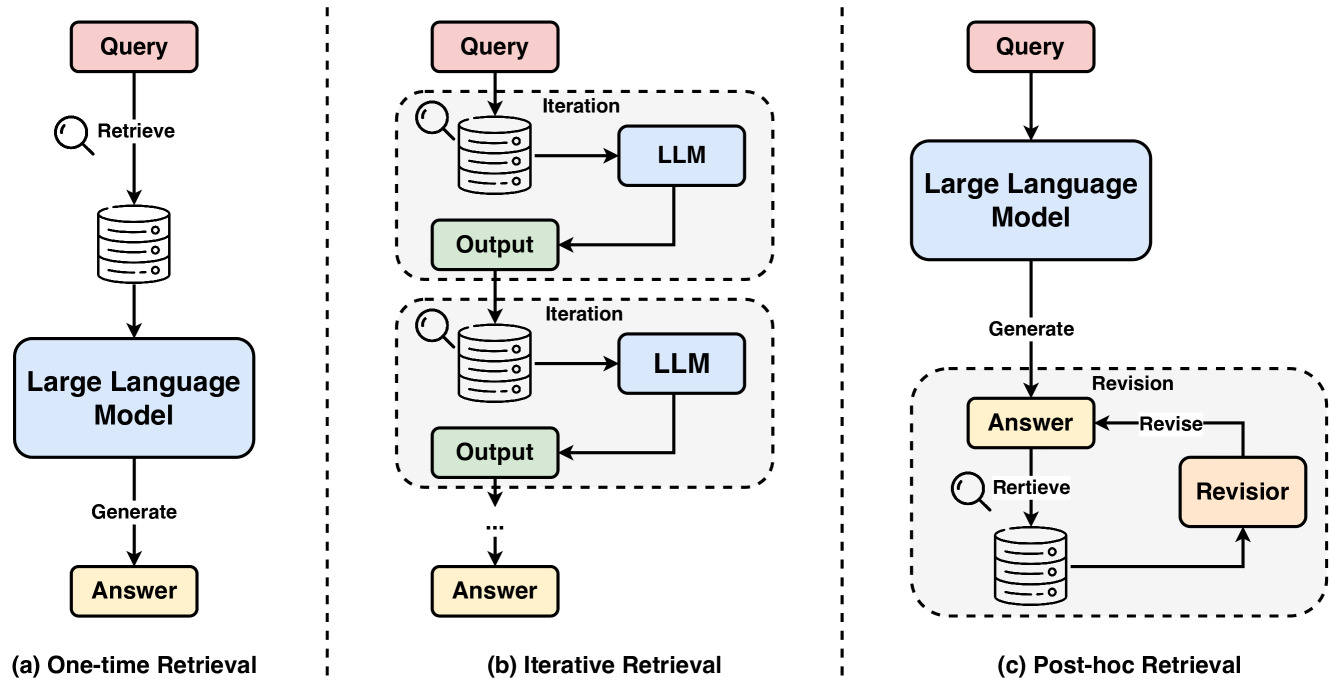
## Diagram: Retrieval-Augmented Generation (RAG) Architectures
### Overview
The image is a technical diagram illustrating three distinct architectural patterns for Retrieval-Augmented Generation (RAG) systems. It is divided into three vertical panels, separated by dashed lines, each depicting a different workflow labeled (a), (b), and (c). The diagram uses a consistent color scheme and iconography to represent components like queries, databases, language models, and outputs.
### Components/Axes
The diagram is not a chart with axes but a flow diagram. The components are represented by colored boxes and icons, connected by directional arrows indicating data flow.
**Common Components & Labels:**
* **Query:** Pink rectangular box. Present at the start of all three workflows.
* **Database/Retrieval Icon:** A gray cylinder with a magnifying glass symbol. Represents the knowledge source or retrieval mechanism.
* **Large Language Model (LLM):** Light blue rounded rectangle. The core processing unit.
* **Output:** Light green rectangular box. Represents intermediate results.
* **Answer:** Light yellow rectangular box. The final generated response.
* **Revisor:** Light orange rectangular box. A component for refining answers.
* **Action Labels:** Text along arrows describes the process step (e.g., "Retrieve", "Generate", "Revise").
* **Process Labels:** Dashed boxes group iterative or revision loops, labeled "Iteration" or "Revision".
**Spatial Layout:**
* **Panel (a) - Left:** Titled "(a) One-time Retrieval". A linear, top-to-bottom flow.
* **Panel (b) - Center:** Titled "(b) Iterative Retrieval". Features a repeating loop within a dashed "Iteration" box.
* **Panel (c) - Right:** Titled "(c) Post-hoc Retrieval". Features a linear generation step followed by a revision loop within a dashed "Revision" box.
### Detailed Analysis
**Panel (a): One-time Retrieval**
1. **Flow:** `Query` -> (Retrieve) -> `Database` -> `Large Language Model` -> (Generate) -> `Answer`.
2. **Description:** This is a straightforward, single-pass architecture. The user query triggers a single retrieval operation from the database. The retrieved information and the original query are then fed into the LLM, which generates the final answer in one step.
**Panel (b): Iterative Retrieval**
1. **Flow:** `Query` -> Enters an `Iteration` loop -> `Database` -> `LLM` -> `Output` -> loops back to `Database` for the next iteration. After one or more iterations, the process exits the loop to produce the final `Answer`.
2. **Description:** This architecture employs a multi-step retrieval process. The system can iteratively refine its understanding by making multiple calls to the database. Each iteration uses the context from the previous `Output` to inform the next retrieval query, potentially gathering more relevant or nuanced information before final answer generation.
**Panel (c): Post-hoc Retrieval**
1. **Flow:** `Query` -> `Large Language Model` -> (Generate) -> `Answer`. This initial `Answer` then enters a `Revision` loop -> (Retrieve) -> `Database` -> `Revisor` -> (Revise) -> back to `Answer`.
2. **Description:** This pattern separates initial generation from verification and refinement. The LLM first generates an answer based on its parametric knowledge. This answer is then passed to a "Revisor" module, which can retrieve supporting or contradicting evidence from the database to fact-check and revise the answer, creating a self-correcting loop.
### Key Observations
1. **Progression of Complexity:** The architectures progress from a simple linear pipeline (a) to systems with internal feedback loops (b and c).
2. **Timing of Retrieval:** The core differentiator is *when* retrieval occurs relative to LLM processing:
* (a) **Before** LLM processing (single time).
* (b) **During** LLM processing (multiple times, interleaved).
* (c) **After** initial LLM processing (for verification).
3. **Component Roles:** The "LLM" in (a) and (b) is the primary answer generator. In (c), the "LLM" is the initial generator, while the "Revisor" is a specialized component for refinement.
4. **Loop Structures:** Panel (b) shows a *generation loop* (improving the answer draft). Panel (c) shows a *revision loop* (correcting a completed draft).
### Interpretation
This diagram effectively contrasts fundamental strategies for integrating external knowledge with Large Language Models. It moves beyond the basic "retrieve-then-generate" model to illustrate more sophisticated, agentic patterns.
* **One-time Retrieval (a)** is the simplest and most common RAG setup, suitable for straightforward QA where a single, focused retrieval is sufficient. Its weakness is a lack of opportunity to correct initial retrieval mistakes.
* **Iterative Retrieval (b)** suggests a more exploratory or complex reasoning process. It mimics how a human might research a topic—performing an initial search, reading the results, and then conducting follow-up searches based on new understanding. This is powerful for multi-faceted questions but increases latency and cost.
* **Post-hoc Retrieval (c)** introduces a critical self-check mechanism. It acknowledges that LLMs can hallucinate or make errors even with retrieved context. By generating an answer first and then challenging it with retrieved evidence, this architecture aims for higher factual reliability and is akin to a "draft and fact-check" workflow. The "Revisor" could be a separate, smaller model or a specialized prompting strategy.
The diagram visually argues that advanced RAG systems are not static pipelines but dynamic processes involving loops of retrieval, generation, and evaluation. The choice between these architectures involves a trade-off between simplicity, depth of reasoning, and computational cost.