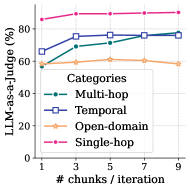
## Chart: LLM-as-a-Judge Performance vs. Number of Chunks/Iteration
### Overview
The image is a line chart comparing the performance of a Large Language Model (LLM) acting as a judge across different question categories (Multi-hop, Temporal, Open-domain, and Single-hop) as the number of chunks/iteration increases. The y-axis represents the percentage of agreement with a human judge (LLM-as-a-Judge (%)), and the x-axis represents the number of chunks per iteration.
### Components/Axes
* **X-axis:** "# chunks / iteration" with markers at 1, 3, 5, 7, and 9.
* **Y-axis:** "LLM-as-a-Judge (%)" with a scale from 0 to 80 in increments of 20.
* **Legend (Center-Right):**
* Multi-hop (Green line with circle markers)
* Temporal (Blue line with square markers)
* Open-domain (Orange line with star markers)
* Single-hop (Pink line with circle markers)
### Detailed Analysis
* **Multi-hop (Green):** Starts at approximately 58% at 1 chunk/iteration, increases to about 70% at 3 chunks/iteration, then to approximately 73% at 5 chunks/iteration, and plateaus around 76% at 7 and 9 chunks/iteration.
* **Temporal (Blue):** Starts at approximately 66% at 1 chunk/iteration, increases to about 75% at 3 chunks/iteration, then to approximately 77% at 5 chunks/iteration, and plateaus around 76% at 7 and 9 chunks/iteration.
* **Open-domain (Orange):** Starts at approximately 58% at 1 chunk/iteration, increases to about 60% at 3 chunks/iteration, plateaus around 61% at 5 and 7 chunks/iteration, and decreases to approximately 58% at 9 chunks/iteration.
* **Single-hop (Pink):** Starts at approximately 86% at 1 chunk/iteration, increases to about 88% at 3 chunks/iteration, and plateaus around 88% at 5, 7, and 9 chunks/iteration.
### Key Observations
* Single-hop questions consistently achieve the highest LLM-as-a-Judge percentage.
* Open-domain questions have the lowest LLM-as-a-Judge percentage.
* The performance of Multi-hop and Temporal questions improves significantly from 1 to 3 chunks/iteration, then plateaus.
* The performance of Open-domain questions remains relatively stable across different numbers of chunks/iteration.
* The performance of Single-hop questions remains relatively stable across different numbers of chunks/iteration.
### Interpretation
The chart suggests that the type of question significantly impacts the LLM's ability to act as a judge. Single-hop questions, which likely require less complex reasoning, are easier for the LLM to evaluate. Multi-hop and Temporal questions benefit from an increased number of chunks/iteration, indicating that providing more context or breaking down the problem into smaller steps improves the LLM's judgment. Open-domain questions, which may require external knowledge or more nuanced understanding, are the most challenging for the LLM to evaluate, and increasing the number of chunks/iteration does not significantly improve performance. The plateauing effect observed for Multi-hop and Temporal questions suggests that there is a limit to how much additional context can improve the LLM's judgment in these categories.