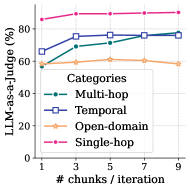
## Line Chart: LLM-as-a-Judge Performance by Task Category
### Overview
This image is a line chart illustrating the performance of an "LLM-as-a-Judge" metric across four distinct task categories as the number of chunks per iteration increases. The chart tracks how increasing the data volume (chunks) affects the judge's accuracy or score across different types of reasoning tasks.
### Components/Axes
* **Vertical Axis (Y-axis):**
* **Label:** LLM-as-a-Judge (%)
* **Scale:** 0 to 100, with major tick marks every 20 units (0, 20, 40, 60, 80).
* **Horizontal Axis (X-axis):**
* **Label:** # chunks / iteration
* **Scale:** Discrete values: 1, 3, 5, 7, 9.
* **Legend:**
* **Placement:** Located in the center-left to bottom-left region of the plot area, enclosed in a white box with a light border.
* **Categories:**
* **Multi-hop:** Teal/Dark Green line with solid circular markers.
* **Temporal:** Dark Blue line with open square markers.
* **Open-domain:** Light Orange/Tan line with open star markers.
* **Single-hop:** Magenta/Pink line with solid circular markers.
* **Grid:** A light gray dashed grid is present across the background of the plot.
### Detailed Analysis
The chart contains four data series. Values below are approximate based on visual alignment with the axes.
| # chunks / iteration | Single-hop (Magenta) | Temporal (Blue) | Multi-hop (Teal) | Open-domain (Orange) |
| :--- | :--- | :--- | :--- | :--- |
| **1** | ~86% | ~66% | ~57% | ~58% |
| **3** | ~89% | ~76% | ~69% | ~59% |
| **5** | ~89% | ~76% | ~71% | ~61% |
| **7** | ~90% | ~76% | ~76% | ~60% |
| **9** | ~90% | ~77% | ~78% | ~58% |
#### Trend Verification:
* **Single-hop (Top-most line):** Slopes upward slightly from 1 to 3 chunks and then plateaus, maintaining the highest performance throughout.
* **Temporal (Second from top at start):** Slopes upward sharply from 1 to 3 chunks, then remains almost perfectly flat through 9 chunks.
* **Multi-hop (Third from top at start):** Slopes upward steadily across the entire range, eventually crossing the Temporal line at 7 chunks and ending as the second-highest series.
* **Open-domain (Bottom-most line):** Remains relatively flat with a very slight peak at 5 chunks before trending slightly downward toward 9 chunks.
### Key Observations
* **Performance Ceiling:** The "Single-hop" category consistently outperforms all others, starting at a high baseline (~86%) and reaching a near-ceiling of ~90%.
* **Diminishing Returns:** For "Temporal" and "Single-hop" tasks, increasing the number of chunks beyond 3 provides negligible performance gains.
* **Growth Potential:** "Multi-hop" tasks show the most significant and sustained improvement as the number of chunks increases, suggesting these tasks benefit more from additional context or data iterations.
* **Stagnation:** "Open-domain" performance is largely unaffected by the number of chunks, hovering around the 60% mark.
### Interpretation
The data suggests that the complexity of the task determines how much an LLM judge benefits from increased data chunks.
* **Single-hop** tasks are likely straightforward enough that the judge reaches peak accuracy with very little context.
* **Multi-hop** tasks, which require connecting multiple pieces of information, show a clear positive correlation between data volume and judge performance, indicating that more "chunks" help the model resolve complex dependencies.
* **Temporal** tasks seem to require a specific threshold of information (reached at 3 chunks) to be judged effectively, after which additional data does not help.
* **Open-domain** tasks may be limited by the model's internal knowledge or the quality of the chunks rather than the quantity, as increasing chunks does not lead to a performance breakthrough.