\n
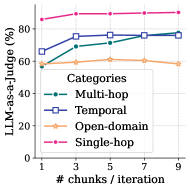
## Line Chart: LLM-as-a-Judge Performance vs. Chunk Size
### Overview
This line chart depicts the performance of a Large Language Model (LLM) used as a judge, measured as a percentage, across four different categories of tasks. The performance is plotted against the number of chunks per iteration, ranging from 1 to 9. The chart illustrates how performance changes as the chunk size increases for each category.
### Components/Axes
* **X-axis:** "# chunks / iteration" - Ranges from 1 to 9, with markers at 1, 3, 5, 7, and 9.
* **Y-axis:** "LLM-as-a-Judge (%)" - Ranges from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located in the top-right corner, identifying the four categories:
* Multi-hop (Teal dashed line)
* Temporal (Blue square line)
* Open-domain (Peach line)
* Single-hop (Magenta dashed line)
### Detailed Analysis
* **Single-hop (Magenta):** The line starts at approximately 84% at chunk size 1 and increases slightly to around 87% at chunk size 9. The trend is generally flat, with a slight upward slope.
* **Temporal (Blue):** The line begins at approximately 65% at chunk size 1, rises to around 74% at chunk size 3, plateaus around 76% at chunk size 5, and remains relatively stable at approximately 76-77% for chunk sizes 7 and 9. The trend is initially upward, then flattens.
* **Open-domain (Peach):** The line starts at approximately 58% at chunk size 1, increases to around 63% at chunk size 3, then declines to approximately 59% at chunk size 9. The trend is initially upward, then downward.
* **Multi-hop (Teal):** The line begins at approximately 70% at chunk size 1, increases to around 75% at chunk size 3, plateaus around 76% at chunk size 5, and remains relatively stable at approximately 76-77% for chunk sizes 7 and 9. The trend is initially upward, then flattens.
### Key Observations
* Single-hop consistently exhibits the highest performance across all chunk sizes.
* Temporal and Multi-hop show similar performance trends, increasing initially and then plateauing.
* Open-domain demonstrates a different pattern, with an initial increase followed by a decline in performance.
* The performance differences between categories become more pronounced at larger chunk sizes (7 and 9).
### Interpretation
The data suggests that increasing the number of chunks per iteration generally improves the LLM's performance as a judge, particularly for Temporal and Multi-hop tasks. However, beyond a certain point (around 3-5 chunks), the performance gains diminish. The Open-domain category's declining performance with increasing chunk size is an anomaly, potentially indicating that larger chunks introduce noise or complexity that negatively impacts the LLM's ability to judge in this domain. The consistently high performance of Single-hop suggests that this type of task is less sensitive to chunk size or that the LLM is particularly well-suited for it. The chart highlights the importance of optimizing chunk size for specific task categories to maximize LLM performance. The plateauing of Temporal and Multi-hop suggests a point of diminishing returns, where further increasing chunk size does not yield significant improvements.