\n
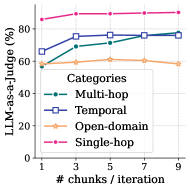
## Line Chart: LLM-as-a-Judge Performance vs. Iterative Chunking
### Overview
The image is a line chart plotting the performance of a Large Language Model (LLM) acting as a judge ("LLM-as-a-judge") against the number of chunks processed per iteration. The chart compares performance across four distinct task categories: Multi-hop, Temporal, Open-domain, and Single-hop. The data suggests that increasing the number of chunks per iteration generally improves or maintains performance, with varying degrees of impact across the different task types.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** "# chunks / iteration"
* **Scale:** Linear, from 1 to 9.
* **Tick Marks:** 1, 3, 5, 7, 9.
* **Y-Axis:**
* **Label:** "LLM-as-a-judge (%)"
* **Scale:** Linear, from 0 to 100.
* **Tick Marks:** 0, 20, 40, 60, 80, 100.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Title:** "Categories"
* **Entries (with corresponding visual markers):**
1. **Multi-hop:** Teal line with solid circle markers.
2. **Temporal:** Blue line with open square markers.
3. **Open-domain:** Orange line with open diamond markers.
4. **Single-hop:** Pink/Magenta line with plus sign (+) markers.
### Detailed Analysis
**Trend Verification & Data Point Extraction (Approximate Values):**
1. **Single-hop (Pink line with + markers):**
* **Trend:** The line starts very high and shows a slight, steady upward slope, indicating consistently excellent performance that improves marginally with more chunks.
* **Data Points:**
* At x=1: ~95%
* At x=3: ~96%
* At x=5: ~97%
* At x=7: ~97.5%
* At x=9: ~98%
2. **Temporal (Blue line with open square markers):**
* **Trend:** The line shows a clear upward trend, starting moderately high and improving steadily, nearly converging with the Multi-hop line at the highest chunk count.
* **Data Points:**
* At x=1: ~65%
* At x=3: ~70%
* At x=5: ~75%
* At x=7: ~78%
* At x=9: ~80%
3. **Multi-hop (Teal line with solid circle markers):**
* **Trend:** The line shows the most significant positive slope, starting lower than Temporal but improving rapidly to match and slightly surpass it by the end.
* **Data Points:**
* At x=1: ~55%
* At x=3: ~68%
* At x=5: ~75%
* At x=7: ~78%
* At x=9: ~80%
4. **Open-domain (Orange line with open diamond markers):**
* **Trend:** The line is relatively flat, showing only a very slight upward trend. Performance is consistently the lowest among the four categories and appears less sensitive to the number of chunks per iteration.
* **Data Points:**
* At x=1: ~50%
* At x=3: ~52%
* At x=5: ~53%
* At x=7: ~54%
* At x=9: ~55%
### Key Observations
1. **Performance Hierarchy:** There is a clear and consistent performance hierarchy across all tested chunk counts: Single-hop > Temporal ≈ Multi-hop > Open-domain.
2. **Convergence:** The performance lines for Temporal and Multi-hop tasks converge as the number of chunks increases, meeting at approximately 80% at 9 chunks/iteration.
3. **Sensitivity to Chunking:** Multi-hop tasks show the greatest sensitivity (steepest slope) to increased chunking, suggesting this parameter is particularly beneficial for complex reasoning tasks. Open-domain tasks show the least sensitivity.
4. **Ceiling Effect:** Single-hop performance starts near the theoretical maximum (100%) and shows minimal room for improvement, indicating a potential ceiling effect for this task type with the current setup.
### Interpretation
This chart demonstrates how the operational parameter of "chunks per iteration" affects an LLM's evaluative performance on different types of reasoning tasks. The data suggests a Peircean inference:
* **For complex, structured reasoning (Multi-hop, Temporal):** Providing more context (chunks) in a single iteration significantly aids the model's judgment capability. The convergence of these two lines implies that with sufficient context, the model's ability to handle sequential (Temporal) and multi-step inferential (Multi-hop) reasoning becomes similarly effective.
* **For broad, factoid-based reasoning (Open-domain):** Performance is lower and largely unaffected by this parameter. This indicates that the challenge in open-domain QA for the LLM-as-a-judge may not be a lack of context within an iteration, but perhaps issues related to knowledge retrieval, ambiguity, or the inherent difficulty of verifying facts across a wide domain.
* **For simple, direct reasoning (Single-hop):** The task is so straightforward for the model that it performs near-perfectly even with minimal context, and additional chunks provide negligible benefit.
**Anomaly/Notable Point:** The most striking finding is the stark difference in slope between the Open-domain line and the others. This visual disconnect suggests that the underlying factors limiting performance in open-domain tasks are fundamentally different from those in more structured reasoning tasks, and are not addressed by simply increasing the iterative context window.