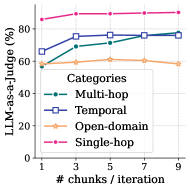
## Line Graph: LLM-as-a-Judge Performance Across Chunk Iterations
### Overview
The image is a line graph comparing the performance of four LLM categories ("Multi-hop," "Temporal," "Open-domain," and "Single-hop") as evaluated by an LLM-as-a-judge metric. Performance is measured in percentage (%) on the y-axis, while the x-axis represents the number of "chunks / iteration" (discrete values: 1, 3, 5, 7, 9). Four distinct data series are plotted with unique colors and markers.
### Components/Axes
- **X-axis**: Labeled "# chunks / iteration" with discrete values (1, 3, 5, 7, 9).
- **Y-axis**: Labeled "LLM-as-a-judge (%)" with a range from 0% to 80%.
- **Legend**: Located in the bottom-right corner, mapping categories to colors/markers:
- **Multi-hop**: Green line with circular markers (○).
- **Temporal**: Blue line with square markers (■).
- **Open-domain**: Orange line with triangular markers (▲).
- **Single-hop**: Pink line with diamond markers (◆).
### Detailed Analysis
1. **Multi-hop (Green ○)**:
- Starts at ~55% at 1 chunk, rises to ~70% at 3 chunks, ~75% at 5 chunks, ~78% at 7 chunks, and plateaus at ~79% at 9 chunks.
- **Trend**: Steady upward trajectory with diminishing returns after 5 chunks.
2. **Temporal (Blue ■)**:
- Begins at ~65% at 1 chunk, increases to ~75% at 3 chunks, then stabilizes between ~75% and ~78% from 5 to 9 chunks.
- **Trend**: Sharp initial improvement followed by plateau.
3. **Open-domain (Orange ▲)**:
- Starts at ~58% at 1 chunk, peaks at ~60% at 3 chunks, then declines to ~58% at 5 chunks, ~57% at 7 chunks, and ~56% at 9 chunks.
- **Trend**: Slight initial gain followed by a gradual decline.
4. **Single-hop (Pink ◆)**:
- Maintains a near-flat line at ~85% across all chunk values (1 to 9 chunks).
- **Trend**: Consistently high performance with no significant variation.
### Key Observations
- **Single-hop** consistently outperforms all other categories, maintaining ~85% performance regardless of chunk count.
- **Multi-hop** and **Temporal** show improvement with increased chunks but plateau after 5–7 chunks.
- **Open-domain** exhibits a minor decline in performance after 3 chunks, suggesting potential inefficiency with larger chunk sizes.
- No overlapping data points between categories; all lines remain distinct.
### Interpretation
The graph highlights that **Single-hop** achieves the highest LLM-as-a-judge performance, likely due to its simplicity or inherent design advantages. **Multi-hop** and **Temporal** benefit from increased chunk iterations but face diminishing returns, indicating optimal performance at moderate chunk sizes. **Open-domain** underperforms relative to others, with a slight degradation as chunk size grows, possibly due to complexity or noise in open-domain data. The lack of overlap suggests clear separability between categories, though the reasons for Open-domain's decline warrant further investigation. The x-axis's discrete nature implies experimental iterations rather than continuous scaling, emphasizing the importance of chunk size optimization in LLM evaluation frameworks.