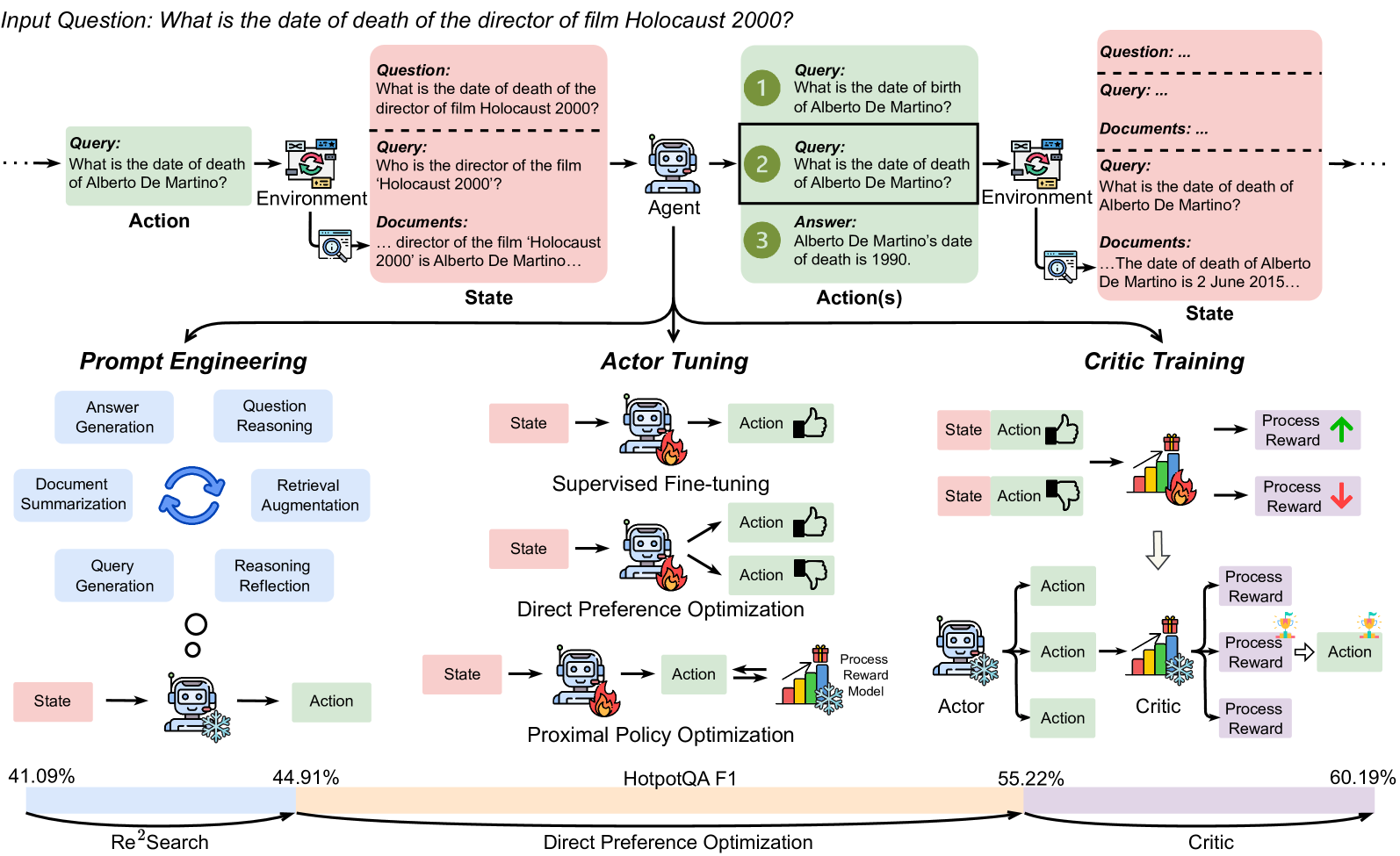
## Diagram: Model Training Pipeline
### Overview
The image illustrates a model training pipeline, comparing three different approaches: Prompt Engineering, Actor Tuning, and Critic Training. The pipeline starts with an input question and progresses through different stages involving an environment, agent, and actions. The diagram highlights the flow of information and processes involved in each training approach, along with performance metrics at the bottom.
### Components/Axes
* **Title:** Input Question: What is the date of death of the director of film Holocaust 2000?
* **Sections:** The diagram is divided into three main sections: Prompt Engineering, Actor Tuning, and Critic Training.
* **Elements:** Each section contains elements such as "State" (pink boxes), "Action" (green boxes), "Environment" (light green boxes), "Agent" (robot icon), "Critic" (trophy icon), and "Process Reward" (arrows).
* **Metrics:** At the bottom, there is a horizontal bar representing "HotpotQA F1" with percentage values.
* **Flow:** Arrows indicate the flow of information and processes.
### Detailed Analysis
**1. Input Question and Initial Setup (Top)**
* The process begins with an "Input Question: What is the date of death of the director of film Holocaust 2000?".
* The question is processed through an "Environment" which involves a "Query: What is the date of death of Alberto De Martino?" and "Documents: ... director of the film 'Holocaust 2000' is Alberto De Martino...". This leads to a "State".
* An "Agent" receives the question and generates "Action(s)". The agent processes the "Query: What is the date of birth of Alberto De Martino?", "Query: What is the date of death of Alberto De Martino?", and provides an "Answer: Alberto De Martino's date of death is 1990."
* The right side shows a similar process with a slightly different "Environment" and "Documents: ... The date of death of Alberto De Martino is 2 June 2015...".
**2. Prompt Engineering (Left)**
* This section focuses on refining the input prompts.
* It includes processes like "Answer Generation", "Question Reasoning", "Document Summarization", "Retrieval Augmentation", "Query Generation", and "Reasoning Reflection".
* The flow involves a "State" leading to an "Action".
* The "HotpotQA F1" score for "Re²Search" is 41.09% to 44.91%.
**3. Actor Tuning (Middle)**
* This section focuses on tuning the "Actor" (the agent).
* It includes "Supervised Fine-tuning" and "Direct Preference Optimization" using "Proximal Policy Optimization".
* The flow involves a "State" leading to an "Action", with feedback mechanisms (thumbs up/down).
* The "HotpotQA F1" score for "Direct Preference Optimization" starts at 44.91% and extends to 55.22%.
**4. Critic Training (Right)**
* This section focuses on training a "Critic" to evaluate the "Actor's" actions.
* The flow involves a "State" leading to an "Action", which is evaluated by the "Critic". The "Critic" provides "Process Reward" feedback.
* The "HotpotQA F1" score for "Critic" starts at 55.22% and extends to 60.19%.
### Key Observations
* The diagram illustrates a comparative analysis of three different training approaches.
* The "Critic Training" approach appears to yield the highest "HotpotQA F1" score (60.19%).
* The diagram highlights the iterative nature of the training process, with feedback loops and refinement at each stage.
### Interpretation
The diagram demonstrates a model training pipeline where different strategies are employed to improve the model's performance in answering complex questions. The "Critic Training" approach, which involves training a separate model to evaluate the agent's actions, seems to be the most effective, as indicated by the highest "HotpotQA F1" score. This suggests that providing explicit feedback on the quality of the agent's responses can significantly enhance its performance. The diagram also underscores the importance of prompt engineering and actor tuning as crucial steps in optimizing the model's ability to understand and answer complex questions.