\n
## Diagram: Reinforcement Learning for Question Answering
### Overview
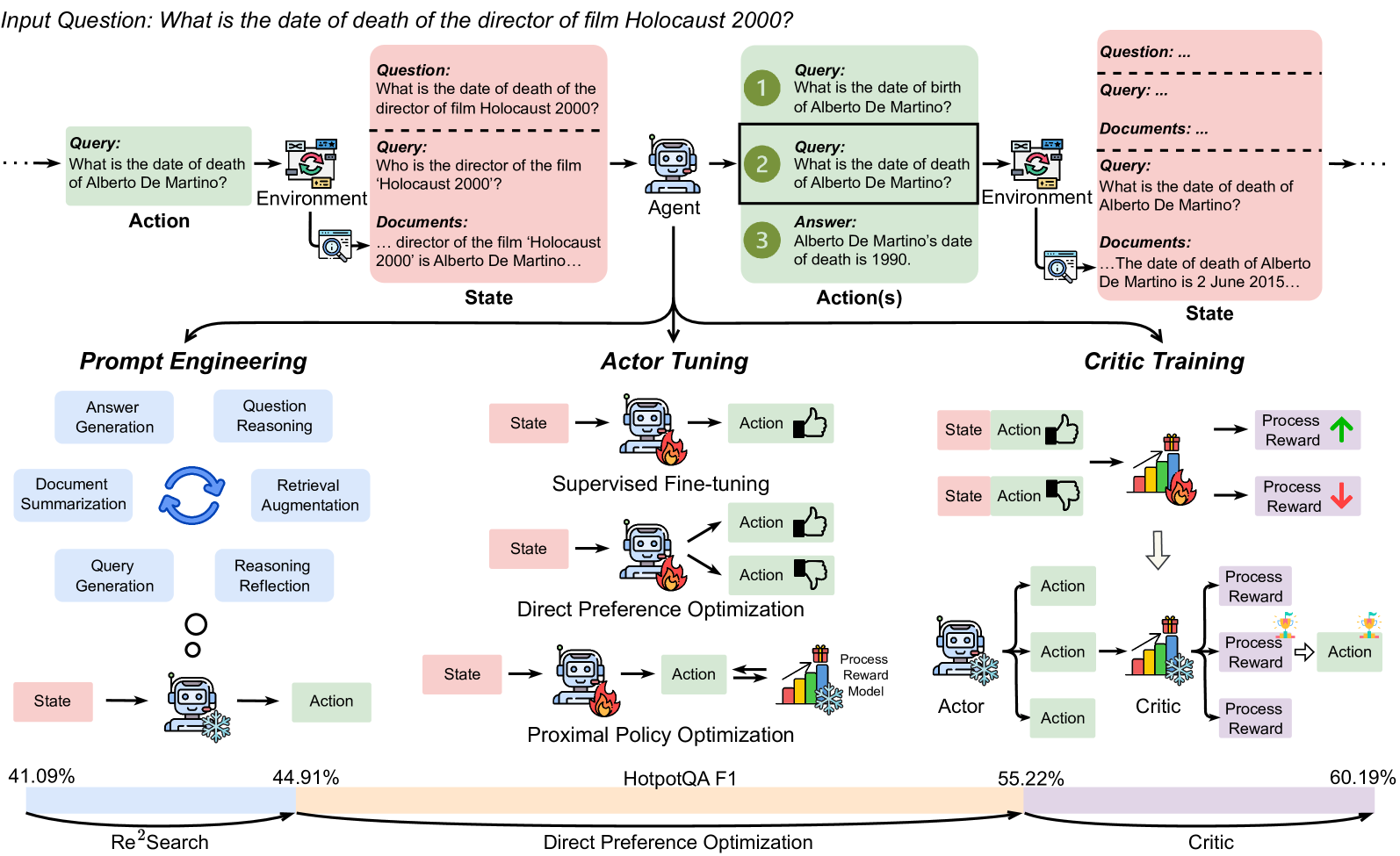
This diagram illustrates a reinforcement learning pipeline for question answering, showcasing the interaction between an agent, environment, and the different stages of training: Prompt Engineering, Actor Tuning, and Critic Training. It depicts the flow of queries, documents, states, actions, and rewards. The diagram also includes performance metrics (F1 scores) for different training methods.
### Components/Axes
The diagram is segmented into three main sections: Prompt Engineering, Actor Tuning, and Critic Training, arranged horizontally. Each section demonstrates a different stage of the reinforcement learning process. The diagram also features a top section illustrating the initial question answering process.
* **Top Section:**
* **Input Question:** "What is the date of death of the director of film Holocaust 2000?"
* **Environment:** Represented by a computer icon.
* **Agent:** Represented by a robot head icon.
* **Query:** Text boxes showing the sequence of queries: "What is the date of death of Alberto De Martino?", "Who is the director of the film Holocaust 2000?", "director of the film 'Holocaust 2000' is Alberto De Martino..."
* **Documents:** Text boxes containing relevant documents.
* **Answer:** "Alberto De Martino's date of death is 1990."
* **State:** Text box labeled "State".
* **Action(s):** Text box labeled "Action(s)".
* **Prompt Engineering:**
* **Components:** Answer Generation, Question Reasoning, Document Summarization, Retrieval Augmentation, Query Generation, Reasoning Reflection.
* **State/Action:** Represented by circular nodes connected by arrows.
* **Actor Tuning:**
* **Components:** Supervised Fine-tuning, Direct Preference Optimization, Proximal Policy Optimization.
* **State/Action:** Represented by rectangular nodes connected by arrows.
* **Critic Training:**
* **Components:** A series of "State Action" pairs leading to "Process Reward" and "Action" nodes.
* **Performance Metrics:** 41.09%, 44.91%, 55.22%, 60.19% (F1 scores).
* **Legend (Implicit):** Colors are used to differentiate the stages and components. Pink represents Prompt Engineering, Blue represents Actor Tuning, and Green represents Critic Training.
* **Labels:** Re²Search, HotpotQA F1, Direct Preference Optimization, Critic.
### Detailed Analysis or Content Details
The diagram illustrates a multi-stage reinforcement learning process.
* **Initial Question Answering (Top Section):** The process begins with an input question. The agent interacts with the environment, formulating queries, retrieving documents, and ultimately arriving at an answer. The example shows the agent correctly determining Alberto De Martino's date of death as 1990.
* **Prompt Engineering:** This stage focuses on refining the prompts used for question answering. It involves components like answer generation, question reasoning, document summarization, retrieval augmentation, query generation, and reasoning reflection. The flow is represented by a circular loop of "State" and "Action". The F1 score is 41.09%.
* **Actor Tuning:** This stage involves training the agent's policy using methods like supervised fine-tuning, direct preference optimization, and proximal policy optimization. Each method is represented by a "State" and "Action" pair. The F1 score is 44.91%.
* **Critic Training:** This stage focuses on training a critic to evaluate the agent's actions. The process involves a series of "State Action" pairs, followed by "Process Reward" and "Action" nodes. The F1 scores increase progressively: 55.22% and 60.19%. The arrows indicate a flow of information and reward signals. The green color consistently represents the Critic Training section.
### Key Observations
* The F1 score progressively increases from Prompt Engineering (41.09%) to Actor Tuning (44.91%) and then to Critic Training (60.19%), indicating improved performance with each stage.
* The Critic Training stage shows two distinct F1 scores (55.22% and 60.19%), potentially representing different iterations or configurations within the critic training process.
* The diagram emphasizes the iterative nature of reinforcement learning, with cycles of state, action, and reward.
* The use of color-coding effectively distinguishes the different stages of the pipeline.
### Interpretation
This diagram demonstrates a reinforcement learning approach to improving question answering systems. The pipeline starts with a basic question answering process and then iteratively refines the system through prompt engineering, actor tuning, and critic training. The increasing F1 scores suggest that each stage contributes to improved performance. The diagram highlights the importance of both policy optimization (Actor Tuning) and value estimation (Critic Training) in achieving high-quality question answering. The diagram suggests that the system learns to formulate better queries, retrieve more relevant documents, and generate more accurate answers through this iterative process. The inclusion of specific methods like Direct Preference Optimization and Proximal Policy Optimization indicates a focus on advanced reinforcement learning techniques. The diagram is a high-level overview of the system and does not provide details on the specific algorithms or implementation details.