TECHNICAL ASSET FINGERPRINT
30ebee6f4da62343e4e9a262
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
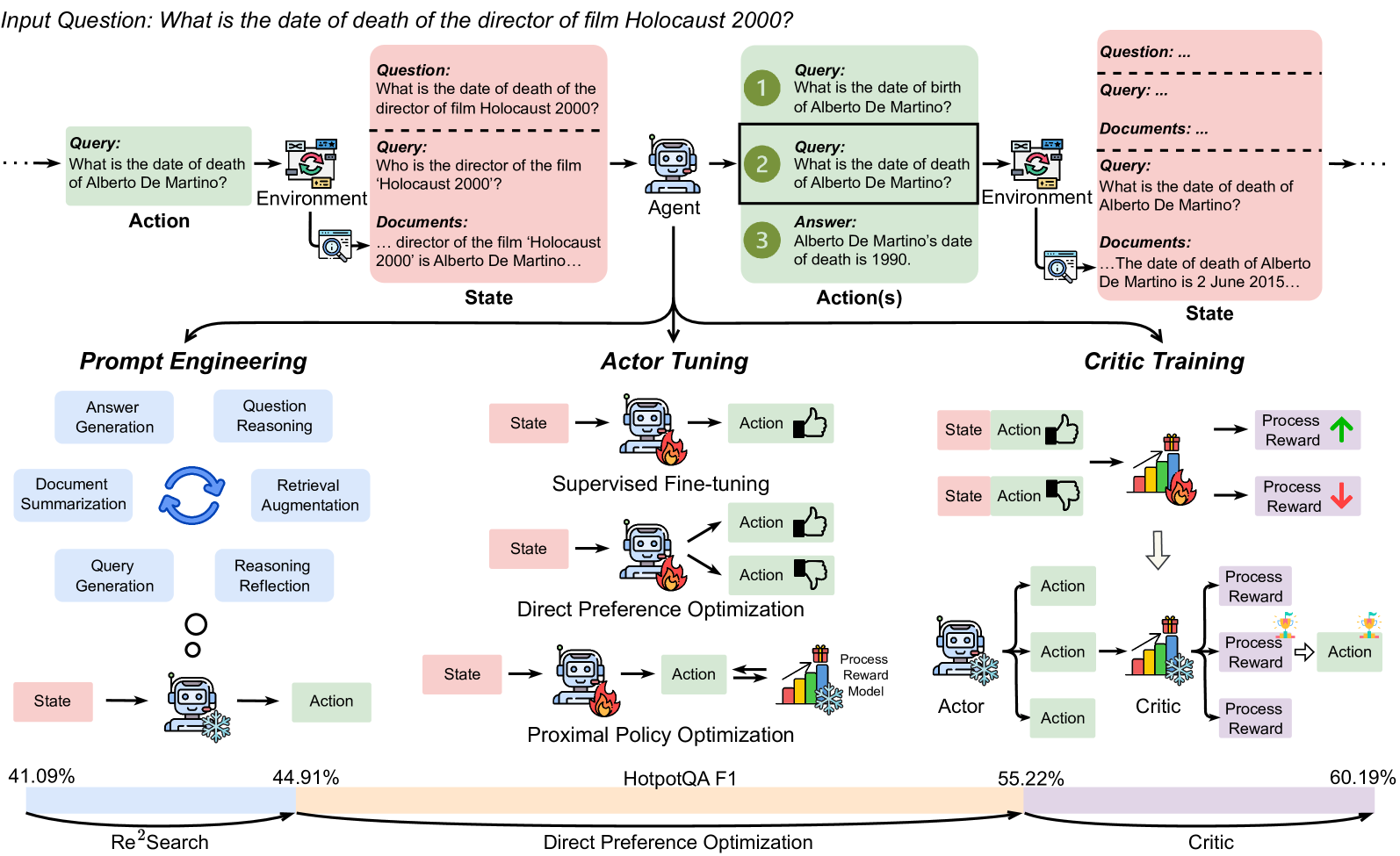
## Diagram: AI Agent Training Pipeline for Multi-Hop Question Answering
### Overview
The image is a technical flowchart illustrating a multi-stage process for training an AI agent to answer complex, multi-hop questions. It uses the example question "What is the date of death of the director of film Holocaust 2000?" to demonstrate how an agent decomposes and solves the problem through interaction with an environment. The diagram details three core training methodologies (Prompt Engineering, Actor Tuning, Critic Training) and shows performance metrics at the bottom.
### Components/Axes
The diagram is organized into three main horizontal sections:
1. **Top Section (Process Flow):** A linear flow from left to right showing the agent's interaction loop.
* **Input Question:** "What is the date of death of the director of film Holocaust 2000?"
* **Action:** "Query: What is the date of death of Alberto De Martino?"
* **Environment:** Represented by a computer monitor icon.
* **State:** A pink box containing:
* "Question: What is the date of death of the director of film Holocaust 2000?"
* "Query: Who is the director of the film 'Holocaust 2000'?"
* "Documents: ... director of the film 'Holocaust 2000' is Alberto De Martino..."
* **Agent:** A robot icon.
* **Action(s):** A green box with three numbered steps:
1. "Query: What is the date of birth of Alberto De Martino?"
2. "Query: What is the date of death of Alberto De Martino?"
3. "Answer: Alberto De Martino's date of death is 1990."
* **Environment:** Another computer monitor icon.
* **State:** A pink box containing:
* "Question: ..."
* "Query: ..."
* "Documents: ..."
* "Query: What is the date of death of Alberto De Martino?"
* "Documents: ... The date of death of Alberto De Martino is 2 June 2015..."
2. **Middle Section (Training Methodologies):** Three parallel columns detailing different training approaches.
* **Left Column - Prompt Engineering:** A cycle of four blue boxes: "Answer Generation", "Question Reasoning", "Retrieval Augmentation", "Document Summarization", "Query Generation", "Reasoning Reflection". Below, a "State" (pink) feeds into an Agent (robot with snowflake icon) which produces an "Action" (green).
* **Center Column - Actor Tuning:** Shows three optimization methods:
* **Supervised Fine-tuning:** "State" -> Agent (robot with fire icon) -> "Action" (thumbs up).
* **Direct Preference Optimization:** "State" -> Agent (robot with fire icon) -> two "Action" outputs (thumbs up and thumbs down).
* **Proximal Policy Optimization:** "State" -> Agent (robot with fire icon) -> "Action" <-> "Process Reward Model" (bar chart with fire icon).
* **Right Column - Critic Training:** Shows a feedback loop.
* Two examples: "State" + "Action" (thumbs up/down) -> "Process Reward" (bar chart with fire icon, green up arrow / red down arrow).
* An "Actor" (robot with snowflake icon) generates multiple "Action" candidates.
* A "Critic" (bar chart with snowflake icon) evaluates them, producing "Process Reward" scores.
* The best "Action" is selected, indicated by a trophy icon.
3. **Bottom Section (Performance Metrics):** A horizontal bar chart showing F1 scores on the HotpotQA benchmark.
* **Y-axis Label:** "HotpotQA F1"
* **Data Points (from left to right):**
* "Re²Search": 41.09%
* "Direct Preference Optimization": 44.91%
* "Critic": 55.22%
* (Final, unlabeled point): 60.19%
* The bar increases in height from left to right, indicating improving performance.
### Detailed Analysis
* **Process Flow Logic:** The diagram demonstrates a multi-hop reasoning chain. The initial question requires two facts: the director's name and then the director's death date. The agent first generates a sub-query to find the director ("Who is the director...?"), receives the answer ("Alberto De Martino") from the environment, and then generates the final query to find the death date. The final state shows a discrepancy: an initial incorrect answer ("1990") is corrected by retrieved documents ("2 June 2015").
* **Training Methodology Details:**
* **Prompt Engineering** is depicted as a cyclical, reflective process involving generating queries, reasoning, and summarizing documents.
* **Actor Tuning** focuses on optimizing the agent's policy (the "Actor"). It compares three techniques: standard supervised learning, learning from preferred vs. non-preferred actions (DPO), and reinforcement learning with a reward model (PPO).
* **Critic Training** introduces a separate "Critic" model to evaluate the quality of actions proposed by the "Actor," providing a process-based reward signal to guide improvement.
* **Performance Trend:** The bottom chart shows a clear, monotonic increase in HotpotQA F1 score across the methods, from 41.09% for a baseline ("Re²Search") to 60.19% for the final "Critic"-based approach. This suggests that the more sophisticated training paradigms (DPO, Critic) yield significant performance gains.
### Key Observations
1. **Iconography:** The diagram uses consistent icons: a robot for the Agent, a computer for the Environment, a bar chart for the Reward Model/Critic. The robot has a "fire" icon during tuning (implying active training) and a "snowflake" icon in the final actor/critic (implying a frozen, deployed state).
2. **Color Coding:** Pink is used for "State" boxes, green for "Action" boxes, and blue for the Prompt Engineering cycle components.
3. **Data Discrepancy:** The example flow contains an intentional error (the agent's initial answer "1990" vs. the correct document answer "2 June 2015") to illustrate the need for retrieval and verification.
4. **Spatial Layout:** The three training methodologies are presented as parallel, alternative, or complementary approaches stemming from the core agent-environment interaction loop shown at the top.
### Interpretation
This diagram outlines a comprehensive framework for moving a question-answering AI from simple retrieval to robust, multi-step reasoning. It argues that beyond basic prompt engineering, performance on complex benchmarks like HotpotQA is significantly enhanced by:
1. **Tuning the Actor:** Directly optimizing the model that generates actions (queries/answers) using techniques like DPO and PPO.
2. **Introducing a Critic:** Separating the roles of action generation (Actor) and action evaluation (Critic). This allows for more nuanced, process-oriented feedback rather than just final-answer correctness.
The progression in the bottom metric chart serves as the key evidence, demonstrating that the integration of a critic model ("Critic" at 55.22% and the final point at 60.19%) provides a substantial leap over earlier methods. The entire pipeline emphasizes an interactive, iterative approach where the agent learns to decompose problems, gather information, and self-correct through structured training.
DECODING INTELLIGENCE...