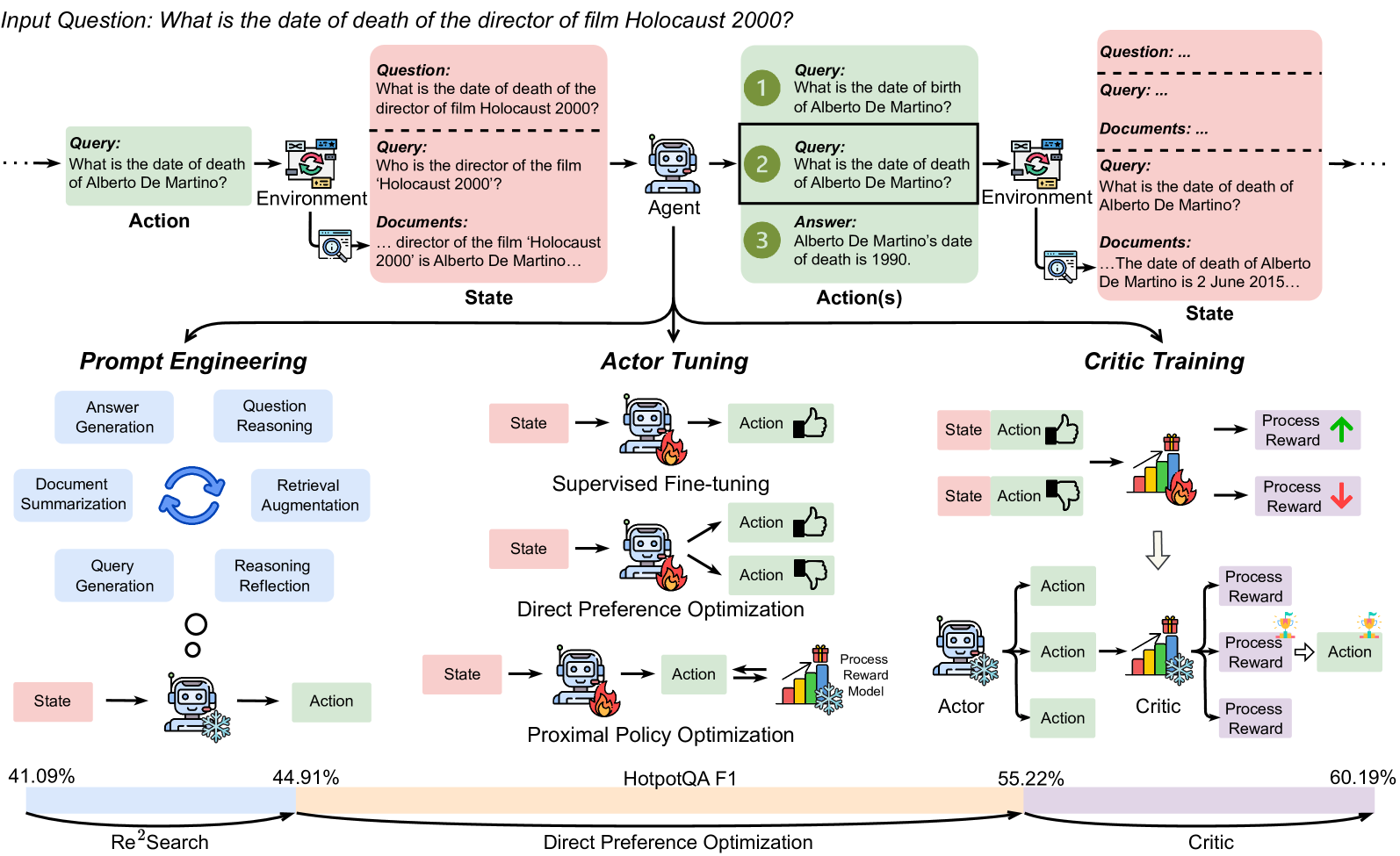
## Flowchart: Multi-Stage Model Optimization Process
### Overview
The diagram illustrates a three-phase optimization pipeline for a question-answering system, progressing from initial query processing to advanced model tuning. Key elements include state-action loops, document retrieval, and performance metrics. The process culminates in a Critic Training phase with the highest reported performance (60.19%).
### Components/Axes
1. **Horizontal Flow Structure**:
- Left to Right: Prompt Engineering → Actor Tuning → Critic Training
- Vertical: State ↔ Action loops with process reward feedback
2. **Key Elements**:
- **State/Action Boxes**: Pink (questions), Green (answers), Blue (documents)
- **Process Reward Model**: Thumbs-up/down icons with bar graphs
- **Performance Metrics**: Bottom axis showing percentages (41.09% to 60.19%)
- **Arrows**: Indicate information flow and feedback loops
3. **Color Coding**:
- Pink: Questions/State
- Green: Answers/Action
- Blue: Documents/Environment
- Purple: Process Reward/Critic
### Detailed Analysis
1. **Prompt Engineering Phase**:
- Input: "What is the date of death of Alberto De Martino?"
- Components: Document retrieval, query generation, reasoning reflection
- Output: State → Action cycle with document summarization
2. **Actor Tuning Phase**:
- Sub-processes:
- Supervised Fine-tuning (thumbs-up icon)
- Direct Preference Optimization (thumbs-down icon)
- Proximal Policy Optimization (snowflake icon)
- Metrics: 44.91% performance
3. **Critic Training Phase**:
- Process Reward Model with explicit feedback (👍/👎)
- Final performance: 60.19%
- Notable: Alberto De Martino death date correction from 1990 to 2015
### Key Observations
1. Performance increases sequentially: 41.09% (Re²Search) → 44.91% (Direct Preference) → 55.22% (Critic) → 60.19% (final)
2. Document retrieval appears in both initial query processing and actor tuning
3. Critic Training introduces explicit user feedback mechanism
4. Alberto De Martino death date discrepancy highlights knowledge correction capability
### Interpretation
This diagram demonstrates a progressive optimization framework where:
1. Initial query processing establishes baseline performance
2. Actor tuning refines model responses through multiple optimization techniques
3. Critic Training introduces human feedback to achieve peak performance
4. The system demonstrates knowledge correction ability through the Alberto De Martino example
The sequential performance improvements suggest that combining document retrieval with iterative optimization and explicit feedback yields the most effective results. The thumbs-up/down system in Critic Training appears crucial for final performance gains, indicating the importance of human-in-the-loop validation in complex QA systems.