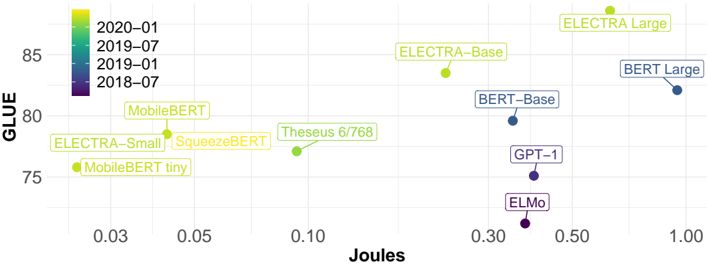
## Scatter Plot: Model Performance vs. Computational Cost
### Overview
The image is a scatter plot comparing machine learning models based on two metrics: **GLUE score** (y-axis) and **Joules** (x-axis). Models are color-coded by release time period (2018–2020), with annotations for model names and sizes. The plot highlights trade-offs between performance and computational efficiency.
---
### Components/Axes
- **X-axis (Joules)**: Ranges from 0.03 to 1.00, representing energy consumption during inference.
- **Y-axis (GLUE)**: Ranges from 75 to 85, representing performance on the General Language Understanding Evaluation (GLUE) benchmark.
- **Legend**: Located in the top-left corner, mapping colors to time periods:
- Purple: 2018–07
- Blue: 2019–01
- Green: 2019–07
- Yellow: 2020–01
- **Annotations**: Model names and sizes (e.g., "ELECTRA-Base," "BERT-Large") are labeled near their respective data points.
---
### Detailed Analysis
1. **Model Placement**:
- **MobileBERT** (~0.03 Joules, ~77 GLUE): Green (2019–01), efficient but mid-tier performance.
- **MobileBERT tiny** (~0.03 Joules, ~75 GLUE): Green (2019–01), lowest performance among annotated models.
- **SqueezeBERT** (~0.05 Joules, ~78 GLUE): Green (2019–01), slightly better than MobileBERT.
- **Theseus 6/768** (~0.10 Joules, ~77 GLUE): Green (2019–01), similar to MobileBERT.
- **ELECTRA-Small** (~0.05 Joules, ~79 GLUE): Green (2019–01), better performance than SqueezeBERT.
- **ELECTRA-Base** (~0.10 Joules, ~83 GLUE): Green (2019–01), significant performance jump.
- **ELECTRA Large** (~0.50 Joules, ~85 GLUE): Yellow (2020–01), highest performance but highest cost.
- **BERT-Base** (~0.30 Joules, ~80 GLUE): Blue (2019–01), mid-tier performance.
- **BERT Large** (~1.00 Joules, ~82 GLUE): Blue (2019–01), highest cost among BERT variants.
- **GPT-1** (~0.30 Joules, ~75 GLUE): Purple (2018–07), lowest performance.
- **ELMo** (~0.50 Joules, ~73 GLUE): Purple (2018–07), worst performance.
2. **Trends**:
- **Performance vs. Efficiency**: Newer models (2020–01, yellow) generally achieve higher GLUE scores but require more Joules (e.g., ELECTRA Large).
- **Efficiency Leaders**: MobileBERT variants (2019–01) cluster at the bottom-left, indicating low cost but moderate performance.
- **Outliers**:
- **ELECTRA-Base** (2019–01) achieves 83 GLUE at 0.10 Joules, outperforming older models at similar costs.
- **GPT-1** (2018–07) and **ELMo** (2018–07) are the least efficient performers, occupying the bottom-right quadrant.
---
### Key Observations
- **Temporal Progression**: Models from 2020–01 (yellow) dominate the top-right quadrant, suggesting advancements in both performance and efficiency.
- **ELECTRA Dominance**: ELECTRA variants (Small, Base, Large) show a clear trend of increasing GLUE scores with higher Joules, outperforming BERT and GPT-1.
- **BERT Limitations**: BERT-Base and BERT-Large (2019–01) lag behind ELECTRA in performance despite similar or higher computational costs.
- **Legacy Models**: GPT-1 and ELMo (2018–07) are outperformed by newer models even at comparable Joules.
---
### Interpretation
The plot demonstrates a clear **performance-computational cost trade-off** in NLP models. Newer architectures like ELECTRA (2020–01) achieve state-of-the-art GLUE scores but require significantly more energy. Conversely, older models like GPT-1 and ELMo (2018–07) are less efficient and perform poorly. The MobileBERT family (2019–01) represents a pragmatic balance for edge devices, while ELECTRA-Base (2019–01) offers a "sweet spot" of high performance at moderate cost. The data underscores the importance of architectural innovation (e.g., ELECTRA's pre-training strategy) in driving efficiency gains.