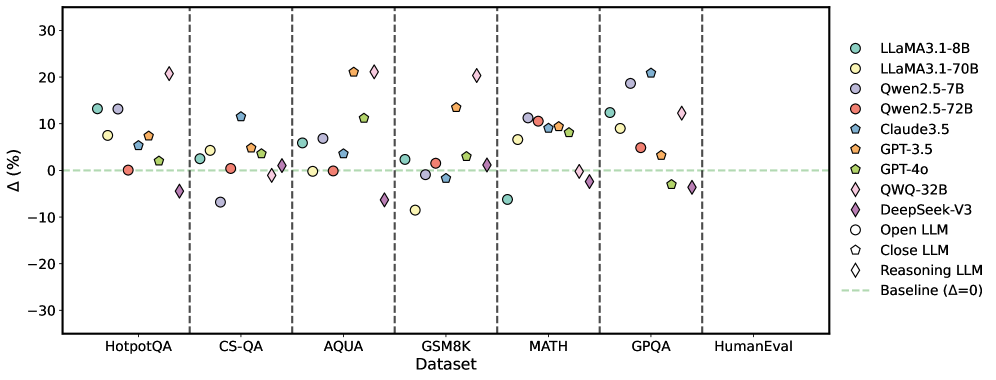
## Scatter Plot: Performance Comparison of Large Language Models
### Overview
This scatter plot compares the performance of various Large Language Models (LLMs) across seven different datasets. The y-axis represents the performance difference (Δ) in percentage points relative to a baseline, while the x-axis lists the datasets used for evaluation. Each point on the plot represents the performance of a specific LLM on a specific dataset. Vertical dashed lines separate the datasets.
### Components/Axes
* **X-axis:** Dataset - with the following categories: HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, HumanEval.
* **Y-axis:** Δ (%) - Performance difference in percentage points. The scale ranges from approximately -30% to 30%.
* **Legend:** Located in the top-right corner, identifies each LLM with a corresponding color and marker shape. The LLMs are:
* LLaMA3-1-8B (Light Blue Circle)
* LLaMA3-1-70B (Light Orange Circle)
* Qwen2.5-7B (Dark Blue Circle)
* Qwen2.5-72B (Red Circle)
* Claude3.5 (Teal Square)
* GPT-3.5 (Orange Triangle)
* GPT-40 (Dark Orange Triangle)
* QWQ-32B (Purple Diamond)
* DeepSeek-V3 (Magenta Diamond)
* Open LLM (Grey Circle)
* Close LLM (Light Grey Hexagon)
* Reasoning LLM (Light Blue Diamond)
* Baseline (Δ=0) (Yellow Star)
### Detailed Analysis
The data points are scattered across the plot, indicating varying performance levels for each LLM on each dataset.
* **HotpotQA:**
* LLaMA3-1-8B: Approximately 5%
* LLaMA3-1-70B: Approximately 8%
* Qwen2.5-7B: Approximately 2%
* Qwen2.5-72B: Approximately 4%
* Claude3.5: Approximately 8%
* GPT-3.5: Approximately 6%
* GPT-40: Approximately 10%
* QWQ-32B: Approximately 18%
* DeepSeek-V3: Approximately 10%
* Open LLM: Approximately 2%
* Close LLM: Approximately 0%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
* **CS-QA:**
* LLaMA3-1-8B: Approximately 5%
* LLaMA3-1-70B: Approximately 10%
* Qwen2.5-7B: Approximately 2%
* Qwen2.5-72B: Approximately 8%
* Claude3.5: Approximately 10%
* GPT-3.5: Approximately 6%
* GPT-40: Approximately 10%
* QWQ-32B: Approximately 20%
* DeepSeek-V3: Approximately 8%
* Open LLM: Approximately 0%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
* **AQUA:**
* LLaMA3-1-8B: Approximately 0%
* LLaMA3-1-70B: Approximately 10%
* Qwen2.5-7B: Approximately -5%
* Qwen2.5-72B: Approximately 5%
* Claude3.5: Approximately 10%
* GPT-3.5: Approximately 5%
* GPT-40: Approximately 10%
* QWQ-32B: Approximately 15%
* DeepSeek-V3: Approximately 5%
* Open LLM: Approximately -5%
* Close LLM: Approximately -10%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
* **GSM8K:**
* LLaMA3-1-8B: Approximately 5%
* LLaMA3-1-70B: Approximately 10%
* Qwen2.5-7B: Approximately 0%
* Qwen2.5-72B: Approximately 5%
* Claude3.5: Approximately 10%
* GPT-3.5: Approximately 5%
* GPT-40: Approximately 10%
* QWQ-32B: Approximately 10%
* DeepSeek-V3: Approximately 5%
* Open LLM: Approximately 0%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
* **MATH:**
* LLaMA3-1-8B: Approximately 10%
* LLaMA3-1-70B: Approximately 10%
* Qwen2.5-7B: Approximately 5%
* Qwen2.5-72B: Approximately 10%
* Claude3.5: Approximately 10%
* GPT-3.5: Approximately 5%
* GPT-40: Approximately 10%
* QWQ-32B: Approximately 10%
* DeepSeek-V3: Approximately 5%
* Open LLM: Approximately 0%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
* **GPQA:**
* LLaMA3-1-8B: Approximately 10%
* LLaMA3-1-70B: Approximately 15%
* Qwen2.5-7B: Approximately 5%
* Qwen2.5-72B: Approximately 10%
* Claude3.5: Approximately 20%
* GPT-3.5: Approximately 10%
* GPT-40: Approximately 10%
* QWQ-32B: Approximately 15%
* DeepSeek-V3: Approximately 10%
* Open LLM: Approximately 0%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
* **HumanEval:**
* LLaMA3-1-8B: Approximately 10%
* LLaMA3-1-70B: Approximately 10%
* Qwen2.5-7B: Approximately 5%
* Qwen2.5-72B: Approximately 5%
* Claude3.5: Approximately 10%
* GPT-3.5: Approximately 5%
* GPT-40: Approximately 5%
* QWQ-32B: Approximately 10%
* DeepSeek-V3: Approximately 5%
* Open LLM: Approximately 0%
* Close LLM: Approximately -5%
* Reasoning LLM: Approximately 10%
* Baseline: 0%
### Key Observations
* QWQ-32B consistently performs well across all datasets, often showing the highest performance difference.
* LLaMA3-1-70B generally outperforms LLaMA3-1-8B.
* Qwen2.5-72B generally outperforms Qwen2.5-7B.
* The "Close LLM" consistently shows negative or near-zero performance differences.
* The "Reasoning LLM" generally performs well, often comparable to GPT-40.
* The "Baseline" is consistently at 0% as expected.
### Interpretation
The plot demonstrates a clear comparison of LLM performance across a range of challenging datasets. The varying performance differences (Δ) highlight the strengths and weaknesses of each model. QWQ-32B appears to be a strong performer overall, while the "Close LLM" seems to struggle to outperform the baseline. The consistent positive Δ for many models suggests that these LLMs generally outperform the baseline model on these tasks. The differences in performance between the 7B and 70B versions of LLaMA3 and Qwen2.5 indicate that model size plays a significant role in performance. The data suggests that the choice of LLM should be tailored to the specific dataset and task, as no single model consistently outperforms all others. The negative values for "Close LLM" suggest that this model may be less effective or require further optimization.