\n
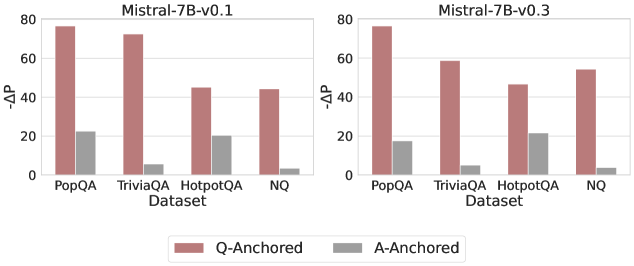
## Bar Chart: ΔP Performance Comparison of Mistral Models
### Overview
The image presents a bar chart comparing the performance difference (ΔP) of two Mistral language models (Mistral-7B-v0.1 and Mistral-7B-v0.3) across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The performance is measured for two anchoring methods: Q-Anchored and A-Anchored.
### Components/Axes
* **X-axis:** "Dataset" with categories: PopQA, TriviaQA, HotpotQA, NQ.
* **Y-axis:** "ΔP" (Delta P), ranging from 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **Legend:** Located at the bottom-center of the image.
* "Q-Anchored" - represented by a light red color.
* "A-Anchored" - represented by a gray color.
* **Titles:** Two titles are present, one above each set of bars:
* "Mistral-7B-v0.1"
* "Mistral-7B-v0.3"
### Detailed Analysis
**Mistral-7B-v0.1:**
* **PopQA:** Q-Anchored: approximately 78. A-Anchored: approximately 24.
* **TriviaQA:** Q-Anchored: approximately 75. A-Anchored: approximately 8.
* **HotpotQA:** Q-Anchored: approximately 50. A-Anchored: approximately 20.
* **NQ:** Q-Anchored: approximately 52. A-Anchored: approximately 28.
**Mistral-7B-v0.3:**
* **PopQA:** Q-Anchored: approximately 80. A-Anchored: approximately 20.
* **TriviaQA:** Q-Anchored: approximately 60. A-Anchored: approximately 6.
* **HotpotQA:** Q-Anchored: approximately 48. A-Anchored: approximately 24.
* **NQ:** Q-Anchored: approximately 62. A-Anchored: approximately 30.
For both models, the Q-Anchored bars are consistently higher than the A-Anchored bars across all datasets, indicating better performance with Q-Anchoring.
### Key Observations
* The performance difference between Q-Anchored and A-Anchored is substantial across all datasets for both models.
* Mistral-7B-v0.3 generally shows improved performance compared to Mistral-7B-v0.1, particularly in PopQA and TriviaQA.
* PopQA consistently yields the highest ΔP values for both models and both anchoring methods.
* TriviaQA consistently yields the lowest ΔP values for both models and both anchoring methods.
### Interpretation
The data suggests that Q-Anchoring consistently outperforms A-Anchoring for both Mistral-7B-v0.1 and Mistral-7B-v0.3 across the tested datasets. This implies that anchoring the prompt with the question (Q-Anchored) is more effective than anchoring it with the answer (A-Anchored) for these models. The improved performance of Mistral-7B-v0.3 indicates that updates to the model have resulted in better performance on these question-answering tasks. The varying performance across datasets suggests that the models' effectiveness is influenced by the characteristics of the datasets themselves (e.g., complexity, domain). The large difference in ΔP for PopQA suggests that this dataset is particularly well-suited to the capabilities of these models, while TriviaQA presents a greater challenge. The consistent trend across both models suggests a robust finding, rather than a dataset-specific anomaly.