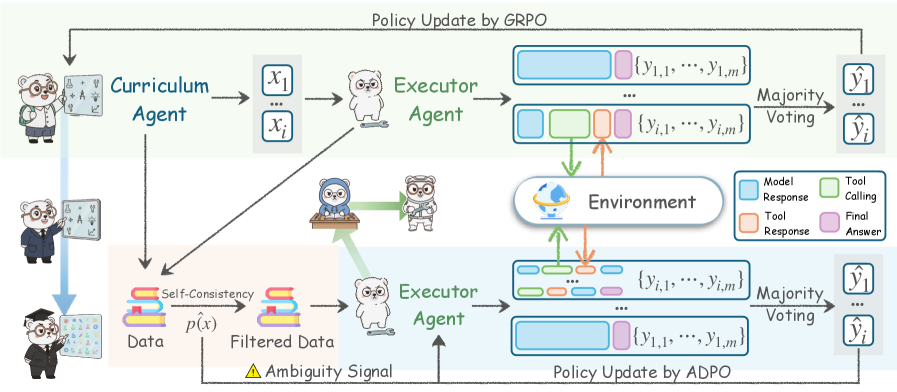
## Diagram: GRPO and ADPO Policy Update
### Overview
The image is a diagram illustrating two different policy update mechanisms: GRPO (top) and ADPO (bottom). Both mechanisms involve a curriculum agent, an executor agent, and an environment. The diagram highlights the flow of information and actions between these components, including model responses, tool calling, tool responses, and final answers.
### Components/Axes
* **Title:** Policy Update by GRPO (top) and Policy Update by ADPO (bottom)
* **Agents:** Curriculum Agent, Executor Agent
* **Data:** Data, Filtered Data
* **Environment:** Environment
* **Processes:** Self-Consistency, Majority Voting
* **Signals:** Ambiguity Signal
* **Variables:** x1, xi, p(x), y1,1 ... y1,m, yi,1 ... yi,m, ŷ1, ŷi
* **Legend (bottom-right):**
* Model Response (light blue)
* Tool Calling (light green)
* Tool Response (light orange)
* Final Answer (light purple)
### Detailed Analysis
1. **GRPO (Top)**
* A "Curriculum Agent" (bear with a blackboard) feeds data `x1` to `xi` to an "Executor Agent" (bear with a wrench).
* The "Executor Agent" generates model responses (light blue), tool calling (light green), and tool responses (light orange) represented as `{y1,1, ..., y1,m}` and `{yi,1, ..., yi,m}`.
* These responses interact with the "Environment" (globe icon).
* The model responses (light blue) and tool responses (light orange) are combined via "Majority Voting" to produce a final answer `ŷ1` to `ŷi` (light purple).
2. **ADPO (Bottom)**
* "Data" undergoes "Self-Consistency" and filtering `p(x)` to become "Filtered Data".
* An "Ambiguity Signal" (yellow triangle) is present below the "Filtered Data".
* The "Filtered Data" is fed to an "Executor Agent" (bear with a wrench).
* The "Executor Agent" generates model responses (light blue), tool calling (light green), and tool responses (light orange) represented as `{y1,1, ..., y1,m}` and `{yi,1, ..., yi,m}`.
* These responses interact with the "Environment" (globe icon).
* The model responses (light blue) and tool responses (light orange) are combined via "Majority Voting" to produce a final answer `ŷ1` to `ŷi` (light purple).
### Key Observations
* Both GRPO and ADPO use a Curriculum Agent and Executor Agent architecture.
* GRPO directly uses data from the Curriculum Agent, while ADPO filters the data first.
* ADPO incorporates a self-consistency check and ambiguity signal, suggesting a mechanism for handling uncertainty or noisy data.
* Both methods use majority voting to aggregate responses from the Executor Agent.
* The environment interacts with both tool calling and tool responses.
### Interpretation
The diagram illustrates two different approaches to policy updates in a system involving agents and an environment. GRPO appears to be a more direct approach, while ADPO incorporates data filtering and ambiguity detection, potentially making it more robust to noisy or inconsistent data. The use of majority voting in both methods suggests an ensemble approach to decision-making. The interaction with the environment indicates that the agents' actions have consequences and provide feedback for further learning or adaptation. The "Ambiguity Signal" in ADPO suggests a mechanism for identifying and potentially mitigating uncertainty in the data or the agent's understanding of the environment.