\n
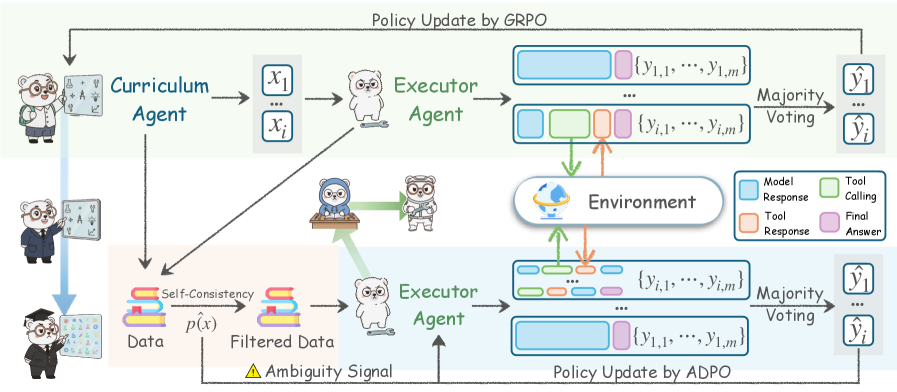
## Diagram: Agent-Based System with Curriculum and Executor Agents
### Overview
The image depicts a diagram of an agent-based system involving a Curriculum Agent and an Executor Agent, interacting with an Environment. The system appears to utilize a feedback loop for policy updates, employing both GRPO and ADPO methods. The diagram illustrates the flow of data, signals, and responses between these components. The diagram uses cartoon bear-like characters to represent the agents.
### Components/Axes
The diagram consists of the following key components:
* **Curriculum Agent:** Represented by a bear character teaching at a chalkboard.
* **Executor Agent:** Represented by a bear character with goggles.
* **Environment:** A central component with a depiction of a landscape and a flowchart-like structure representing interactions.
* **Data:** Represented by a bear character with a spreadsheet.
* **Policy Update by GRPO:** A process occurring at the top of the diagram.
* **Policy Update by ADPO:** A process occurring at the bottom of the diagram.
* **Self-Consistency:** A filter applied to the data.
* **Ambiguity Signal:** A signal indicating uncertainty.
* **Model Response:** A component within the Environment.
* **Tool Calling:** A component within the Environment.
* **Tool Response:** A component within the Environment.
* **Final Answer:** A component within the Environment.
The diagram uses arrows to indicate the flow of information and control. Text labels are used to describe the data and processes.
### Detailed Analysis or Content Details
The diagram can be divided into two main sections: the upper path utilizing GRPO policy updates and the lower path utilizing ADPO policy updates.
**Upper Path (GRPO):**
1. The Curriculum Agent generates data points `x1` to `xi`.
2. These data points are passed to the Executor Agent.
3. The Executor Agent generates multiple responses `(y1,1, ..., y1,m)`. These are represented as a series of rectangular blocks.
4. The same process is repeated, generating another set of responses `(y2,1, ..., y2,m)`.
5. A "Majority Voting" process selects the final output `ŷ1` to `ŷj`.
6. The final output is used to update the policy via GRPO.
**Lower Path (ADPO):**
1. The Data (represented by a bear with a spreadsheet) is processed through "Self-Consistency" and "Filtered Data".
2. An "Ambiguity Signal" is generated.
3. The filtered data is passed to the Executor Agent.
4. The Executor Agent generates multiple responses `(y1,1, ..., y1,m)`.
5. The same process is repeated, generating another set of responses `(y2,1, ..., y2,m)`.
6. A "Majority Voting" process selects the final output `ŷ1` to `ŷj`.
7. The final output is used to update the policy via ADPO.
**Environment:**
The Environment receives input from both Executor Agents (upper and lower paths). Within the Environment, the process flows through:
* Model Response
* Tool Calling
* Tool Response
* Final Answer
### Key Observations
* The system employs two distinct policy update mechanisms: GRPO and ADPO.
* Both paths involve an Executor Agent generating multiple responses and a Majority Voting process for selection.
* The lower path incorporates a "Self-Consistency" check and an "Ambiguity Signal," suggesting a mechanism for handling uncertain or inconsistent data.
* The Environment acts as a central hub for processing responses and generating a final answer.
* The use of cartoon bears adds a visual element but does not contribute to the technical information.
### Interpretation
The diagram illustrates a complex agent-based system designed for iterative learning and policy refinement. The Curriculum Agent provides data, while the Executor Agent explores potential solutions. The Environment evaluates these solutions, and the resulting feedback is used to update the policy through either GRPO or ADPO. The inclusion of "Self-Consistency" and "Ambiguity Signal" in the ADPO path suggests a focus on robustness and handling noisy or uncertain data. The majority voting mechanism indicates a strategy for aggregating multiple responses to improve the reliability of the final output.
The two paths (GRPO and ADPO) likely represent different learning strategies or stages within the overall system. GRPO might represent a more direct policy update based on the curriculum, while ADPO might represent a more refined update based on real-world data and uncertainty assessment. The system appears to be designed for tasks requiring both exploration (Executor Agent) and exploitation (Curriculum Agent), with a focus on adapting to changing conditions and handling ambiguity. The diagram is a high-level overview and does not provide details on the specific algorithms or parameters used in each component.