TECHNICAL ASSET FINGERPRINT
31c4a6a8a924e496d742e869
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
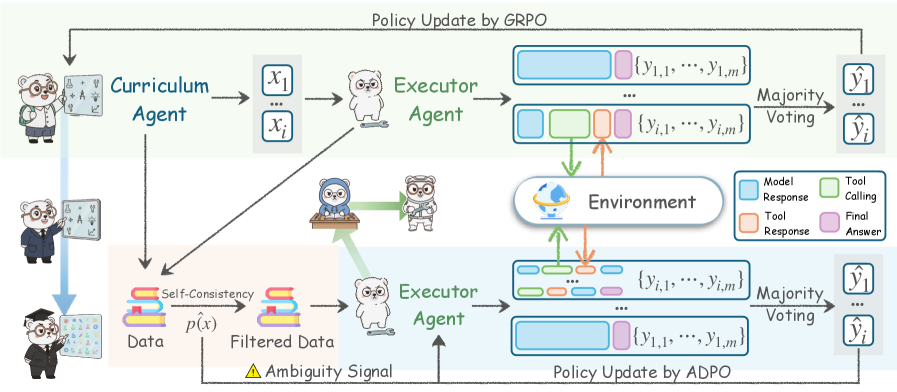
## Diagram: Multi-Agent Reinforcement Learning Training Framework with GRPO and ADPO
### Overview
The image is a technical flowchart illustrating a dual-path reinforcement learning training framework for AI agents. It depicts two parallel policy update methods: **GRPO** (top section) and **ADPO** (bottom section). The system involves multiple specialized agents (Curriculum Agent, Executor Agent) interacting with an Environment to generate, filter, and learn from data sequences, ultimately producing final answers through a majority voting mechanism.
### Components/Axes
The diagram is divided into two primary horizontal sections, each representing a distinct training pipeline.
**1. Upper Section: Policy Update by GRPO**
* **Left Side:** A "Curriculum Agent" (depicted as a cartoon professor) generates input data sequences denoted as `{x₁, ..., xᵢ}`.
* **Center:** An "Executor Agent" (depicted as a cartoon dog) receives the input sequences `{x₁, ..., xᵢ}`.
* **Right Side:** The Executor Agent interacts with an "Environment" (depicted as a globe icon). This interaction produces multiple output sequences `{y_{i,1}, ..., y_{i,m}}`.
* **Legend (Center-Right):** A box defines the color coding for the output sequence blocks:
* **Light Blue:** Model Response
* **Light Green:** Tool Calling
* **Orange:** Tool Response
* **Pink:** Final Answer
* **Final Output:** The multiple output sequences `{y_{i,1}, ..., y_{i,m}}` undergo "Majority Voting" to produce a set of final answers `{ŷᵢ, ..., ŷᵢ}`.
**2. Lower Section: Policy Update by ADPO**
* **Left Side:** The same "Curriculum Agent" generates data. This data flows into a "Data" block.
* **Data Processing Pipeline:**
* The raw "Data" undergoes a "Self-Consistency" check, represented by a circular arrow icon.
* This produces "Filtered Data".
* An "Ambiguity Signal" (marked with a yellow warning triangle ⚠️) is generated from this process and fed back to the "Executor Agent".
* **Center:** An "Executor Agent" (same dog character) receives the "Filtered Data".
* **Right Side:** Similar to the GRPO path, the Executor Agent interacts with the "Environment", generating output sequences `{y_{i,1}, ..., y_{i,m}}`.
* **Final Output:** These sequences also undergo "Majority Voting" to produce final answers `{ŷᵢ, ..., ŷᵢ}`.
**3. Shared Elements & Flow:**
* **Environment:** A central component where Executor Agents perform actions (Tool Calling) and receive feedback (Tool Response).
* **Feedback Loop:** A line labeled "Policy Update by GRPO" connects the final answers from the top section back to the Curriculum Agent, indicating a learning loop.
* **Character Icons:** The Curriculum Agent is shown in three poses (professor, businessman, graduate), possibly representing different stages or roles in data generation.
### Detailed Analysis
**Data Flow & Sequence Structure:**
* **Input:** `{x₁, ..., xᵢ}` - A batch of `i` input prompts or tasks.
* **Output per Input:** For each input `xᵢ`, the Executor Agent generates `m` response sequences `{y_{i,1}, ..., y_{i,m}}`. Each sequence `y_{i,j}` is a composite of colored blocks representing a chain of: Model Response -> (optional Tool Calling -> Tool Response) -> Final Answer.
* **Aggregation:** The `m` sequences for a given input are aggregated via "Majority Voting" to determine the most consistent final answer `ŷᵢ`.
**Key Difference between GRPO and ADPO Paths:**
* **GRPO (Top):** Uses the raw data generated by the Curriculum Agent directly.
* **ADPO (Bottom):** Introduces a **data filtering stage**. The raw data is processed for "Self-Consistency," resulting in "Filtered Data." This process also emits an "Ambiguity Signal" that is fed back to the Executor Agent, likely to guide its learning or sampling strategy towards less ambiguous examples.
### Key Observations
1. **Multi-Agent Architecture:** The framework explicitly separates the roles of data generation (Curriculum Agent) and task execution/learning (Executor Agent).
2. **Ensemble Method:** The use of "Majority Voting" over `m` response sequences (`{y_{i,1}, ..., y_{i,m}}`) for each input is a clear ensemble technique aimed at improving the reliability and robustness of the final answer `ŷᵢ`.
3. **Tool-Augmented Generation:** The color-coded sequence blocks show that the Executor Agent's process is not just text generation. It can invoke external tools (Tool Calling), receive their outputs (Tool Response), and then synthesize a final answer, indicating a **ReAct (Reasoning + Acting)** or similar agent paradigm.
4. **Data Quality Focus in ADPO:** The ADPO path's core innovation appears to be the "Self-Consistency" filter and the resulting "Ambiguity Signal." This suggests ADPO prioritizes training on high-consistency, low-ambiguity data, potentially to stabilize learning or improve performance on clear-cut tasks.
5. **Closed-Loop Learning:** The "Policy Update" arrows feeding final answers back to the Curriculum Agent indicate an iterative, online learning process where the agent's performance influences future data generation.
### Interpretation
This diagram outlines a sophisticated reinforcement learning framework designed to train more capable and reliable AI agents, likely for complex reasoning or tool-use tasks.
* **Core Mechanism:** The system learns by having an Executor Agent attempt tasks multiple times (`m` attempts per task), using a mix of internal reasoning and external tools. The consensus (majority vote) from these attempts is treated as the ground truth for policy update.
* **GRPO vs. ADPO:** The two paths represent different philosophies for improving this process.
* **GRPO** appears to be a more straightforward approach, updating the policy based on the aggregated results from all generated data.
* **ADPO** introduces a **quality control layer**. By filtering data for self-consistency and generating an ambiguity signal, it likely aims to:
1. **Reduce Noise:** Train the agent primarily on examples where its multiple attempts converge, implying the task is well-understood and the solution is stable.
2. **Provide a Learning Signal:** The "Ambiguity Signal" itself could be a valuable training input, teaching the agent to recognize and perhaps avoid or seek clarification on inherently ambiguous problems.
* **Practical Implication:** The ADPO method, while more computationally expensive due to the filtering step, could lead to faster convergence, more robust policies, and agents that are better calibrated about their own uncertainty. The framework as a whole moves beyond simple supervised learning towards a more dynamic, self-improving system where the agent's interaction history directly shapes its future training curriculum.
DECODING INTELLIGENCE...