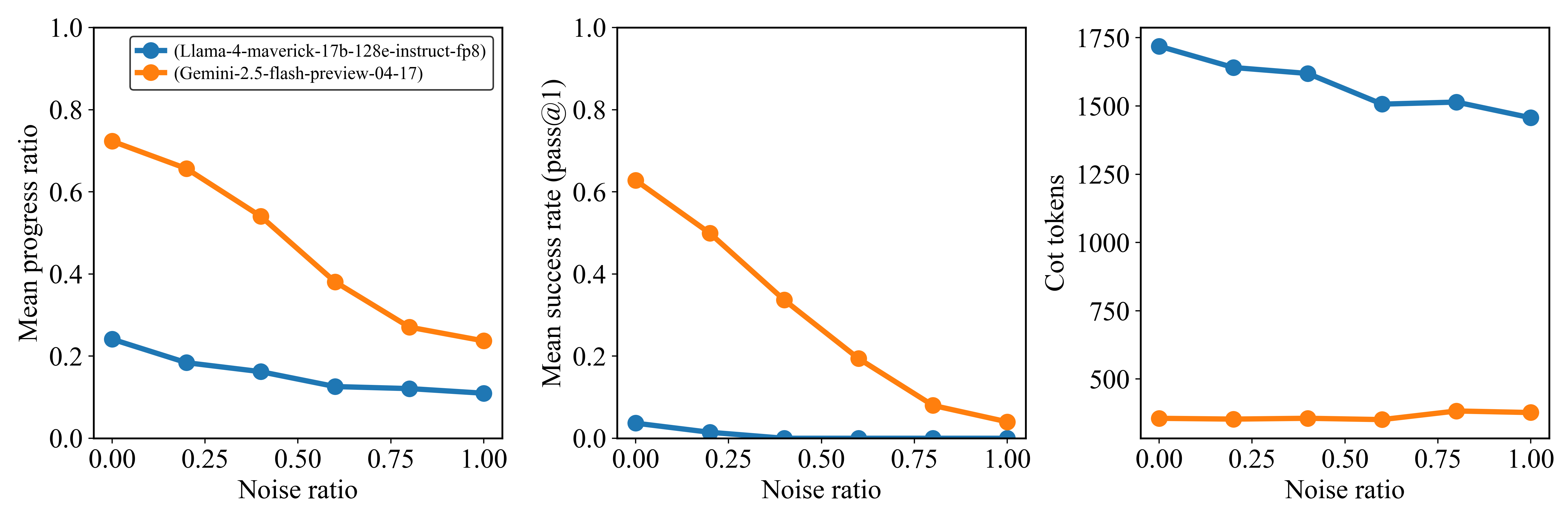
## Line Charts: Model Performance vs. Noise Ratio
### Overview
The image presents three line charts comparing the performance of two language models, "Llama-4-maverick-17b-128e-instruct-fp8" and "Gemini-2.5-flash-preview-04-17", across varying levels of noise. The charts depict "Mean progress ratio", "Mean success rate (pass@1)", and "Cot tokens" as a function of "Noise ratio".
### Components/Axes
**General Chart Elements:**
* **X-axis:** Noise ratio, ranging from 0.00 to 1.00 in increments of 0.25.
* **Legend (Top-Left of First Chart):**
* Blue: (Llama-4-maverick-17b-128e-instruct-fp8)
* Orange: (Gemini-2.5-flash-preview-04-17)
**Chart 1: Mean Progress Ratio**
* **Y-axis:** Mean progress ratio, ranging from 0.0 to 1.0.
**Chart 2: Mean Success Rate (pass@1)**
* **Y-axis:** Mean success rate (pass@1), ranging from 0.0 to 1.0.
**Chart 3: Cot tokens**
* **Y-axis:** Cot tokens, ranging from 0 to 1750 in increments of 250.
### Detailed Analysis
**Chart 1: Mean Progress Ratio**
* **(Llama-4-maverick-17b-128e-instruct-fp8) (Blue):** The line slopes downward slightly.
* Noise Ratio 0.00: Mean progress ratio ~0.24
* Noise Ratio 0.25: Mean progress ratio ~0.18
* Noise Ratio 0.50: Mean progress ratio ~0.16
* Noise Ratio 0.75: Mean progress ratio ~0.13
* Noise Ratio 1.00: Mean progress ratio ~0.12
* **(Gemini-2.5-flash-preview-04-17) (Orange):** The line slopes downward significantly.
* Noise Ratio 0.00: Mean progress ratio ~0.72
* Noise Ratio 0.25: Mean progress ratio ~0.58
* Noise Ratio 0.50: Mean progress ratio ~0.40
* Noise Ratio 0.75: Mean progress ratio ~0.28
* Noise Ratio 1.00: Mean progress ratio ~0.24
**Chart 2: Mean Success Rate (pass@1)**
* **(Llama-4-maverick-17b-128e-instruct-fp8) (Blue):** The line remains near zero.
* Noise Ratio 0.00: Mean success rate ~0.04
* Noise Ratio 0.25: Mean success rate ~0.01
* Noise Ratio 0.50: Mean success rate ~0.00
* Noise Ratio 0.75: Mean success rate ~0.00
* Noise Ratio 1.00: Mean success rate ~0.00
* **(Gemini-2.5-flash-preview-04-17) (Orange):** The line slopes downward significantly.
* Noise Ratio 0.00: Mean success rate ~0.62
* Noise Ratio 0.25: Mean success rate ~0.50
* Noise Ratio 0.50: Mean success rate ~0.30
* Noise Ratio 0.75: Mean success rate ~0.08
* Noise Ratio 1.00: Mean success rate ~0.04
**Chart 3: Cot tokens**
* **(Llama-4-maverick-17b-128e-instruct-fp8) (Blue):** The line slopes downward slightly.
* Noise Ratio 0.00: Cot tokens ~1700
* Noise Ratio 0.25: Cot tokens ~1630
* Noise Ratio 0.50: Cot tokens ~1520
* Noise Ratio 0.75: Cot tokens ~1500
* Noise Ratio 1.00: Cot tokens ~1450
* **(Gemini-2.5-flash-preview-04-17) (Orange):** The line remains relatively constant.
* Noise Ratio 0.00: Cot tokens ~370
* Noise Ratio 0.25: Cot tokens ~370
* Noise Ratio 0.50: Cot tokens ~370
* Noise Ratio 0.75: Cot tokens ~380
* Noise Ratio 1.00: Cot tokens ~390
### Key Observations
* The "Gemini-2.5-flash-preview-04-17" model exhibits a significantly higher mean progress ratio and mean success rate compared to the "Llama-4-maverick-17b-128e-instruct-fp8" model at lower noise ratios.
* The performance of "Gemini-2.5-flash-preview-04-17" degrades substantially as the noise ratio increases in both "Mean progress ratio" and "Mean success rate (pass@1)".
* The "Llama-4-maverick-17b-128e-instruct-fp8" model maintains a relatively stable, but low, mean progress ratio and mean success rate across all noise ratios.
* The number of "Cot tokens" for "Gemini-2.5-flash-preview-04-17" remains relatively constant regardless of the noise ratio, while "Cot tokens" for "Llama-4-maverick-17b-128e-instruct-fp8" decreases slightly as noise increases.
### Interpretation
The data suggests that the "Gemini-2.5-flash-preview-04-17" model is more sensitive to noise than the "Llama-4-maverick-17b-128e-instruct-fp8" model. While "Gemini-2.5-flash-preview-04-17" performs better in low-noise environments, its performance rapidly declines as noise increases. The "Llama-4-maverick-17b-128e-instruct-fp8" model, although less performant in ideal conditions, demonstrates more robustness to noise. The "Cot tokens" metric indicates the complexity or length of the model's reasoning process. The relatively stable "Cot tokens" for "Gemini-2.5-flash-preview-04-17" suggests that the model maintains a consistent reasoning process even as its performance degrades due to noise. The slight decrease in "Cot tokens" for "Llama-4-maverick-17b-128e-instruct-fp8" may indicate a simplification of its reasoning process under noisy conditions.