TECHNICAL ASSET FINGERPRINT
322845a20e88f3bec2216edd
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash
INTEL_VERIFIED
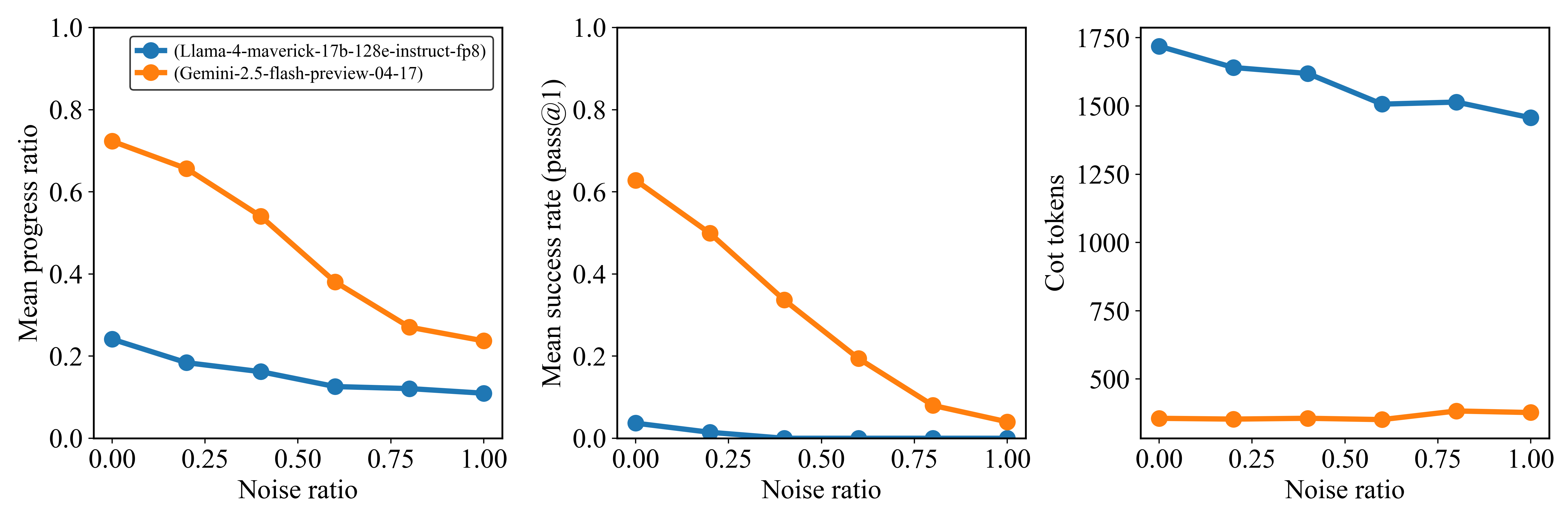
## Chart Type: Performance and Token Usage of Language Models Under Varying Noise Ratios
### Overview
This image presents three line charts arranged horizontally, comparing the performance and token usage of two language models, "Llama-4-maverick-17b-128e-instruct-fp8" and "Gemini-2.5-flash-preview-04-17", across different "Noise ratio" values. The charts illustrate how "Mean progress ratio", "Mean success rate (pass@1)", and "Cot tokens" change as the noise ratio increases from 0.00 to 1.00.
### Components/Axes
The image consists of three sub-charts, each sharing a common X-axis and a common legend.
**Common Elements:**
* **X-axis Label (Bottom of each chart):** "Noise ratio"
* **X-axis Markers (Common to all charts):** 0.00, 0.25, 0.50, 0.75, 1.00
* **Legend (Top-left of the leftmost chart, applies to all three):**
* Blue line with circular markers: "(Llama-4-maverick-17b-128e-instruct-fp8)"
* Orange line with circular markers: "(Gemini-2.5-flash-preview-04-17)"
**Chart 1 (Leftmost): Mean progress ratio vs. Noise ratio**
* **Y-axis Label:** "Mean progress ratio"
* **Y-axis Markers:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
**Chart 2 (Middle): Mean success rate (pass@1) vs. Noise ratio**
* **Y-axis Label:** "Mean success rate (pass@1)"
* **Y-axis Markers:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
**Chart 3 (Rightmost): Cot tokens vs. Noise ratio**
* **Y-axis Label:** "Cot tokens"
* **Y-axis Markers:** 0, 250, 500, 750, 1000, 1250, 1500, 1750
### Detailed Analysis
**Chart 1: Mean progress ratio vs. Noise ratio**
* **Orange Line (Gemini-2.5-flash-preview-04-17):**
* **Trend:** The mean progress ratio for Gemini-2.5-flash-preview-04-17 starts high and shows a significant downward trend as the noise ratio increases. The decline is steeper between 0.50 and 0.75 noise ratio.
* **Data Points:**
* Noise ratio 0.00: ~0.72
* Noise ratio 0.25: ~0.65
* Noise ratio 0.50: ~0.55
* Noise ratio 0.75: ~0.28
* Noise ratio 1.00: ~0.25
* **Blue Line (Llama-4-maverick-17b-128e-instruct-fp8):**
* **Trend:** The mean progress ratio for Llama-4-maverick-17b-128e-instruct-fp8 starts lower than Gemini and also shows a downward trend, but it is much flatter and at consistently lower values.
* **Data Points:**
* Noise ratio 0.00: ~0.24
* Noise ratio 0.25: ~0.18
* Noise ratio 0.50: ~0.15
* Noise ratio 0.75: ~0.13
* Noise ratio 1.00: ~0.12
**Chart 2: Mean success rate (pass@1) vs. Noise ratio**
* **Orange Line (Gemini-2.5-flash-preview-04-17):**
* **Trend:** The mean success rate for Gemini-2.5-flash-preview-04-17 starts high and exhibits a sharp, continuous decline as the noise ratio increases, approaching zero at higher noise levels.
* **Data Points:**
* Noise ratio 0.00: ~0.62
* Noise ratio 0.25: ~0.50
* Noise ratio 0.50: ~0.35
* Noise ratio 0.75: ~0.08
* Noise ratio 1.00: ~0.02
* **Blue Line (Llama-4-maverick-17b-128e-instruct-fp8):**
* **Trend:** The mean success rate for Llama-4-maverick-17b-128e-instruct-fp8 starts very low and declines slightly, remaining close to zero across all noise ratios.
* **Data Points:**
* Noise ratio 0.00: ~0.04
* Noise ratio 0.25: ~0.02
* Noise ratio 0.50: ~0.01
* Noise ratio 0.75: ~0.01
* Noise ratio 1.00: ~0.01
**Chart 3: Cot tokens vs. Noise ratio**
* **Orange Line (Gemini-2.5-flash-preview-04-17):**
* **Trend:** The Cot tokens for Gemini-2.5-flash-preview-04-17 remain relatively stable and low across all noise ratios, with a slight increase at higher noise levels.
* **Data Points:**
* Noise ratio 0.00: ~350
* Noise ratio 0.25: ~350
* Noise ratio 0.50: ~350
* Noise ratio 0.75: ~380
* Noise ratio 1.00: ~380
* **Blue Line (Llama-4-maverick-17b-128e-instruct-fp8):**
* **Trend:** The Cot tokens for Llama-4-maverick-17b-128e-instruct-fp8 start high and show a gradual downward trend as the noise ratio increases.
* **Data Points:**
* Noise ratio 0.00: ~1700
* Noise ratio 0.25: ~1620
* Noise ratio 0.50: ~1580
* Noise ratio 0.75: ~1500
* Noise ratio 1.00: ~1480
### Key Observations
* **Performance Degradation with Noise:** Both "Mean progress ratio" and "Mean success rate (pass@1)" generally decrease as the "Noise ratio" increases for both models.
* **Gemini's Superior Performance (Low Noise):** At low noise ratios (e.g., 0.00 to 0.50), Gemini-2.5-flash-preview-04-17 significantly outperforms Llama-4-maverick-17b-128e-instruct-fp8 in both "Mean progress ratio" and "Mean success rate (pass@1)".
* **Gemini's Steep Decline:** Gemini's performance metrics (progress ratio and success rate) show a much steeper decline with increasing noise compared to Llama. Its success rate drops from ~0.62 at 0.00 noise to ~0.02 at 1.00 noise.
* **Llama's Consistent Low Performance:** Llama-4-maverick-17b-128e-instruct-fp8 maintains a consistently low "Mean progress ratio" and "Mean success rate (pass@1)" across all noise levels, suggesting it is less affected by noise in terms of relative performance change, but its absolute performance is poor.
* **Cot Token Usage Disparity:** Llama-4-maverick-17b-128e-instruct-fp8 uses substantially more "Cot tokens" (around 1500-1700) than Gemini-2.5-flash-preview-04-17 (around 350-380) across all noise ratios.
* **Cot Token Stability:** Gemini's Cot token usage is very stable, slightly increasing with noise. Llama's Cot token usage decreases slightly with increasing noise, but remains high.
### Interpretation
The data suggests a trade-off between performance and resource efficiency, and robustness to noise, between the two language models.
Gemini-2.5-flash-preview-04-17 appears to be a higher-performing model under ideal or low-noise conditions, achieving significantly better "Mean progress ratio" and "Mean success rate (pass@1)". However, its performance degrades sharply as the "Noise ratio" increases, indicating a lower robustness to noisy inputs. Despite its higher performance, Gemini consistently uses a much lower number of "Cot tokens," suggesting it is more efficient in terms of computational steps or reasoning complexity (as measured by CoT tokens).
Conversely, Llama-4-maverick-17b-128e-instruct-fp8 exhibits a much lower baseline performance in both progress ratio and success rate. While its performance also declines with noise, the absolute change is less dramatic because it starts from a much lower point. This might imply that Llama is either inherently less capable for the task or less sensitive to noise due to its lower performance ceiling. Critically, Llama uses a significantly higher number of "Cot tokens" across all noise levels, suggesting it requires more computational effort or generates longer chains of thought, yet yields inferior results compared to Gemini, especially at lower noise. The slight decrease in Llama's Cot tokens with increasing noise might indicate that it struggles to generate coherent chains of thought when inputs are very noisy, leading to shorter outputs, but this doesn't translate to improved performance.
In summary, Gemini offers superior performance and token efficiency in clean environments but is more susceptible to performance drops with increasing noise. Llama, while less efficient in token usage and generally lower performing, shows a relatively flatter (though low) performance curve under varying noise, suggesting a different architectural or training approach that might prioritize some form of stability over peak performance or efficiency. The choice between these models would depend on the expected noise level of the input data and the priority given to performance versus resource consumption.
DECODING INTELLIGENCE...