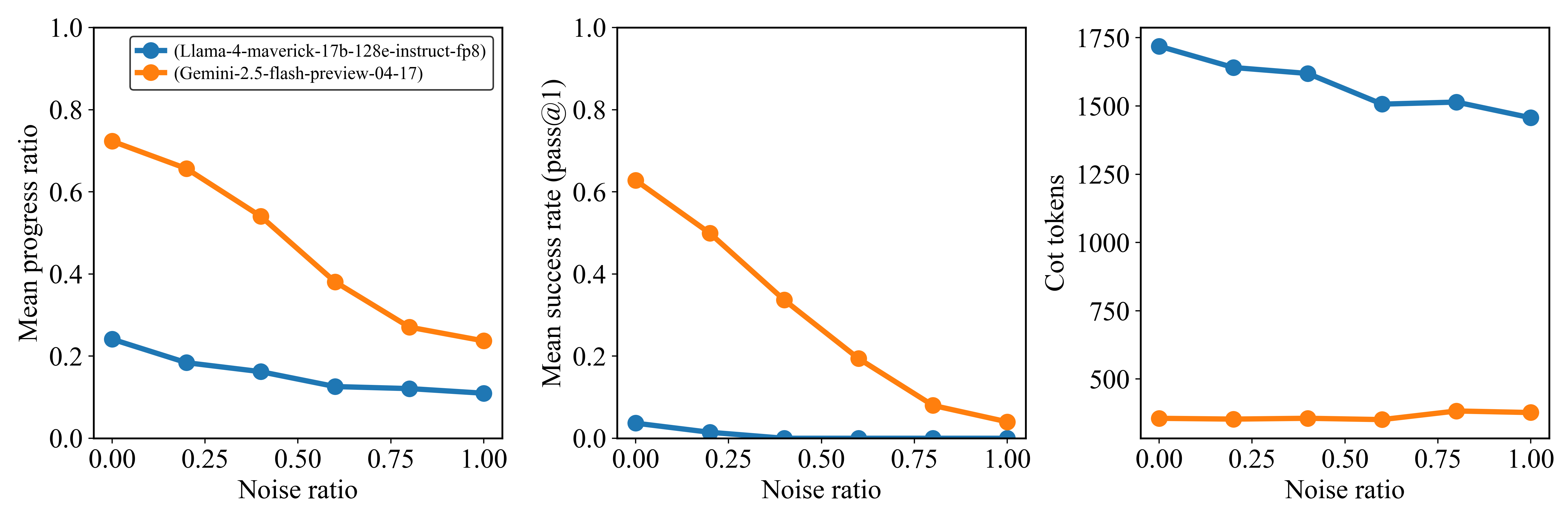
\n
## Charts: Performance of Language Models with Noise Injection
### Overview
This image presents three line charts comparing the performance of two language models, Llama-4-maverick-17b-128e-instruct-fp8 and Gemini-2.5-flash-preview-04-17, under varying levels of noise injection. The charts display Mean Progress Ratio, Mean Success Rate (pass@1), and CoT tokens (Chain-of-Thought tokens) as functions of the Noise Ratio.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Noise Ratio, ranging from 0.00 to 1.00, with markers at 0.00, 0.25, 0.50, 0.75, and 1.00.
* **Y-axis (Left Chart):** Mean Progress Ratio, ranging from 0.00 to 1.00.
* **Y-axis (Middle Chart):** Mean Success Rate (pass@1), ranging from 0.00 to 1.00.
* **Y-axis (Right Chart):** CoT tokens, ranging from 0 to 1750.
* **Legend (Top-Left of each chart):**
* Blue Line: Llama-4-maverick-17b-128e-instruct-fp8
* Orange Line: Gemini-2.5-flash-preview-04-17
### Detailed Analysis
**Chart 1: Mean Progress Ratio vs. Noise Ratio**
* **Llama (Blue Line):** The line slopes downward, indicating a decrease in Mean Progress Ratio as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.24
* At Noise Ratio 0.25: Approximately 0.18
* At Noise Ratio 0.50: Approximately 0.14
* At Noise Ratio 0.75: Approximately 0.12
* At Noise Ratio 1.00: Approximately 0.10
* **Gemini (Orange Line):** The line slopes downward more steeply than Llama, indicating a more significant decrease in Mean Progress Ratio as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.72
* At Noise Ratio 0.25: Approximately 0.52
* At Noise Ratio 0.50: Approximately 0.32
* At Noise Ratio 0.75: Approximately 0.18
* At Noise Ratio 1.00: Approximately 0.08
**Chart 2: Mean Success Rate (pass@1) vs. Noise Ratio**
* **Llama (Blue Line):** The line slopes downward, indicating a decrease in Mean Success Rate as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.18
* At Noise Ratio 0.25: Approximately 0.12
* At Noise Ratio 0.50: Approximately 0.08
* At Noise Ratio 0.75: Approximately 0.06
* At Noise Ratio 1.00: Approximately 0.04
* **Gemini (Orange Line):** The line slopes downward very steeply, indicating a significant decrease in Mean Success Rate as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.82
* At Noise Ratio 0.25: Approximately 0.58
* At Noise Ratio 0.50: Approximately 0.34
* At Noise Ratio 0.75: Approximately 0.14
* At Noise Ratio 1.00: Approximately 0.06
**Chart 3: CoT Tokens vs. Noise Ratio**
* **Llama (Blue Line):** The line shows a slight downward trend, with some fluctuations, indicating a small decrease in CoT tokens as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 1725
* At Noise Ratio 0.25: Approximately 1550
* At Noise Ratio 0.50: Approximately 1475
* At Noise Ratio 0.75: Approximately 1450
* At Noise Ratio 1.00: Approximately 1425
* **Gemini (Orange Line):** The line is relatively flat, with minor fluctuations, indicating a minimal change in CoT tokens as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 475
* At Noise Ratio 0.25: Approximately 500
* At Noise Ratio 0.50: Approximately 525
* At Noise Ratio 0.75: Approximately 500
* At Noise Ratio 1.00: Approximately 525
### Key Observations
* Gemini consistently outperforms Llama in both Mean Progress Ratio and Mean Success Rate at all Noise Ratio levels.
* Both models exhibit a significant performance degradation (decrease in Mean Progress Ratio and Mean Success Rate) as the Noise Ratio increases.
* The number of CoT tokens used by Llama is substantially higher than that used by Gemini, and remains relatively stable across different Noise Ratios. Gemini's CoT token usage is low and relatively constant.
* Gemini's performance is more sensitive to noise than Llama's.
### Interpretation
The data suggests that Gemini is more robust to noise than Llama, maintaining a higher success rate and progress ratio even with significant noise injection. However, Gemini relies on fewer CoT tokens, which might indicate a different reasoning strategy or a more efficient approach to problem-solving. Llama, while more susceptible to noise, utilizes a larger number of CoT tokens, potentially indicating a more verbose or exploratory reasoning process. The steep decline in performance for both models with increasing noise highlights the importance of data quality and the potential vulnerability of language models to adversarial inputs or noisy data. The relatively stable CoT token usage for Llama suggests that the model attempts to maintain its reasoning process even under noisy conditions, while Gemini's minimal token usage indicates a more direct approach that is easily disrupted by noise. The difference in CoT token usage could also be related to the model architectures or training methodologies.