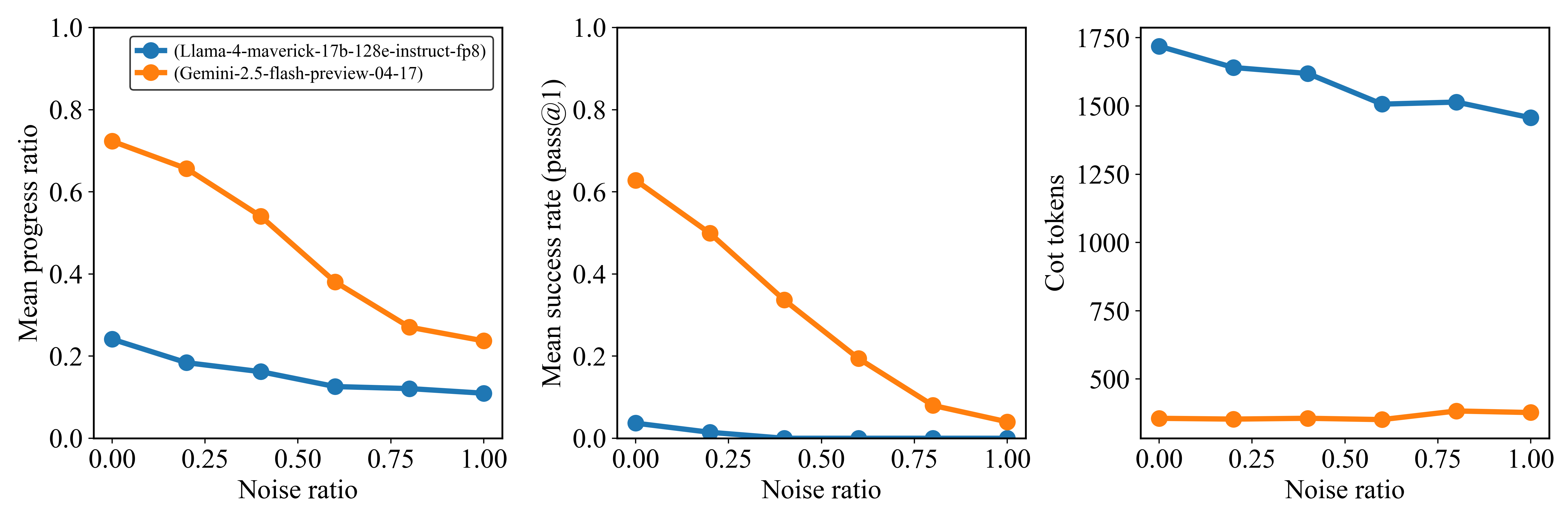
## Line Charts: Model Performance vs Noise Ratio
### Overview
Three line charts compare the performance of two AI models (Llama-4-maverick-17b-128e-instruct-fp8 and Gemini-2.5-flash-preview-04-17) across three metrics as noise ratio increases from 0.00 to 1.00. Each chart uses distinct y-axes for different metrics.
### Components/Axes
1. **X-axis**: Noise ratio (0.00 to 1.00 in 0.25 increments)
2. **Y-axes**:
- Chart 1: Mean progress ratio (0.0 to 1.0)
- Chart 2: Mean success rate (pass@1) (0.0 to 1.0)
- Chart 3: Cot tokens (0 to 1750)
3. **Legends**:
- Blue circles: Llama-4-maverick-17b-128e-instruct-fp8
- Orange circles: Gemini-2.5-flash-preview-04-17
4. **Legend placement**: Top-left corner of each chart
### Detailed Analysis
#### Chart 1: Mean progress ratio
- **Llama (blue)**: Starts at ~0.25, decreases gradually to ~0.12
- **Gemini (orange)**: Starts at ~0.75, decreases steeply to ~0.22
- **Trend**: Both decline, but Gemini shows sharper degradation
#### Chart 2: Mean success rate (pass@1)
- **Llama (blue)**: Starts at ~0.03, drops to near 0
- **Gemini (orange)**: Starts at ~0.62, decreases to ~0.04
- **Trend**: Both collapse at higher noise, Gemini maintains higher values initially
#### Chart 3: Cot tokens
- **Llama (blue)**: Starts at ~1750, decreases to ~1450
- **Gemini (orange)**: Remains flat at ~250
- **Trend**: Llama shows significant computational cost reduction, Gemini stable
### Key Observations
1. **Performance degradation**: Both models deteriorate with noise, but Gemini's decline is more pronounced in progress ratio and success rate
2. **Computational efficiency**: Llama's token usage drops significantly with noise, while Gemini maintains constant low usage
3. **Robustness**: Llama demonstrates better noise resilience in success rate metrics
4. **Threshold behavior**: All metrics show steep declines after noise ratio >0.5
### Interpretation
The data suggests Llama-4 maintains better performance stability under noise compared to Gemini-2.5, particularly in success rate metrics. However, Gemini shows superior computational efficiency with consistent low token usage. The sharp decline in Llama's progress ratio indicates potential overfitting to clean data. The cot token metric reveals Llama's processing becomes more resource-intensive under noise, while Gemini's fixed token usage suggests optimized inference pathways. These findings highlight trade-offs between model robustness and computational efficiency in noisy environments.