\n
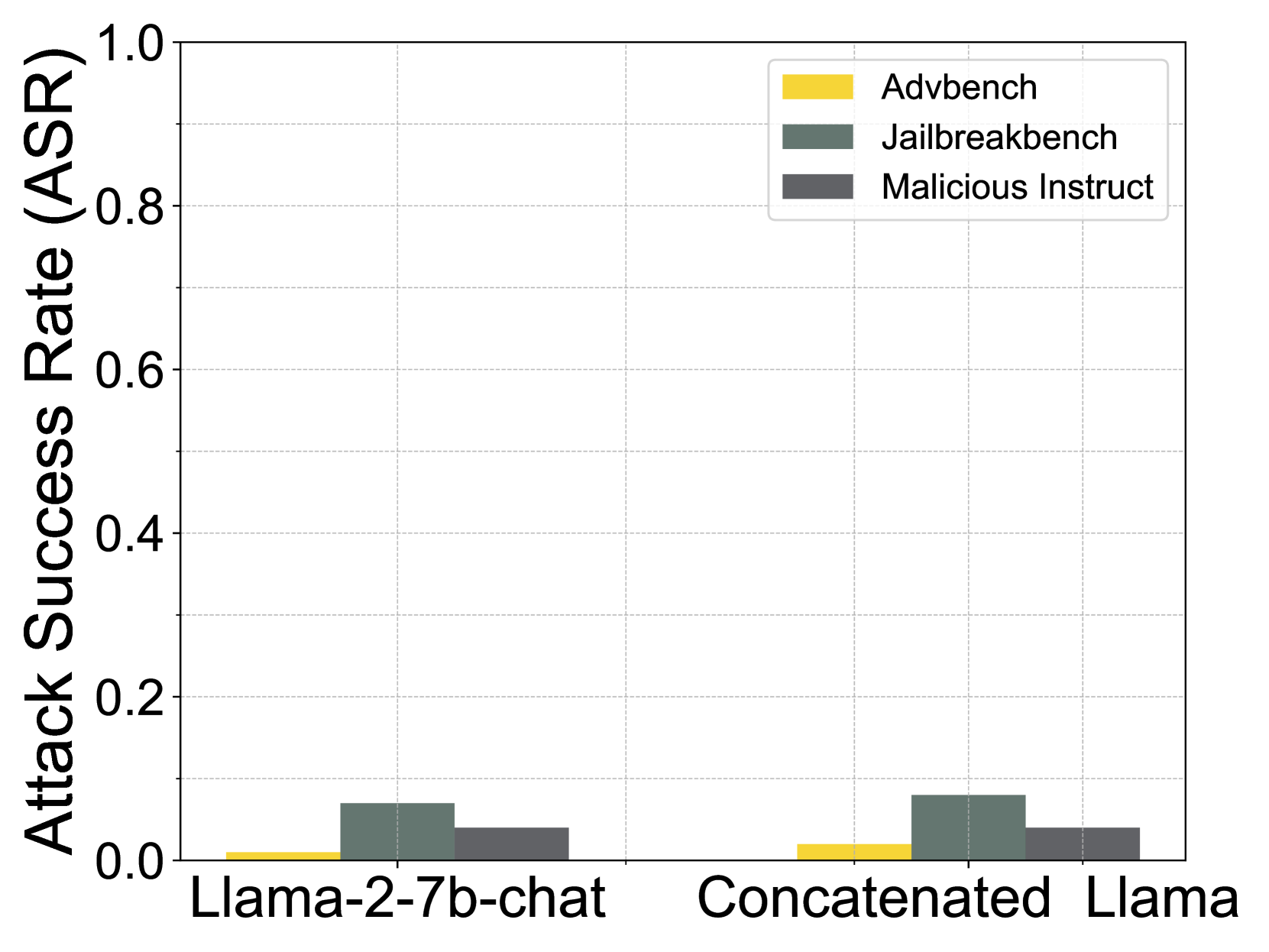
## Bar Chart: Attack Success Rate (ASR) for Different Models
### Overview
This bar chart compares the Attack Success Rate (ASR) of three different language models – Llama-2-7b-chat, Concatenated, and Llama – against three different attack benchmarks: Advbench, Jailbreakbench, and Malicious Instruct. The ASR is represented on the y-axis, ranging from 0.0 to 1.0, while the x-axis displays the model names. Each model has three bars representing its ASR for each attack benchmark.
### Components/Axes
* **Y-axis:** "Attack Success Rate (ASR)" - Scale ranges from 0.0 to 1.0, with increments of 0.2.
* **X-axis:** Model Names - "Llama-2-7b-chat", "Concatenated", "Llama".
* **Legend:** Located in the top-right corner.
* Yellow: "Advbench"
* Gray: "Jailbreakbench"
* Dark Gray: "Malicious Instruct"
### Detailed Analysis
The chart consists of nine bars, grouped by model and attack type.
* **Llama-2-7b-chat:**
* Advbench (Yellow): ASR is approximately 0.02.
* Jailbreakbench (Gray): ASR is approximately 0.04.
* Malicious Instruct (Dark Gray): ASR is approximately 0.04.
* **Concatenated:**
* Advbench (Yellow): ASR is approximately 0.04.
* Jailbreakbench (Gray): ASR is approximately 0.04.
* Malicious Instruct (Dark Gray): ASR is approximately 0.04.
* **Llama:**
* Advbench (Yellow): ASR is approximately 0.02.
* Jailbreakbench (Gray): ASR is approximately 0.04.
* Malicious Instruct (Dark Gray): ASR is approximately 0.04.
All bars are very close to zero, indicating a low attack success rate across all models and benchmarks.
### Key Observations
* The ASR values are consistently low for all models and attack types.
* There is no significant difference in ASR between the three models.
* Advbench and Jailbreakbench have slightly lower ASRs than Malicious Instruct, but the difference is minimal.
* The chart shows that all models are relatively robust against these three attack benchmarks.
### Interpretation
The data suggests that the tested language models (Llama-2-7b-chat, Concatenated, and Llama) exhibit a high degree of resistance to the specified attack benchmarks (Advbench, Jailbreakbench, and Malicious Instruct). The consistently low ASR values across all combinations indicate that these models are not easily susceptible to adversarial attacks designed to elicit unintended or harmful responses. The similarity in ASR across the three models suggests that their underlying defenses against these types of attacks are comparable. The slight variation in ASR between the benchmarks might indicate that certain attack strategies are marginally more effective than others, but the overall robustness of the models remains high. This information is valuable for assessing the security and reliability of these language models in real-world applications.