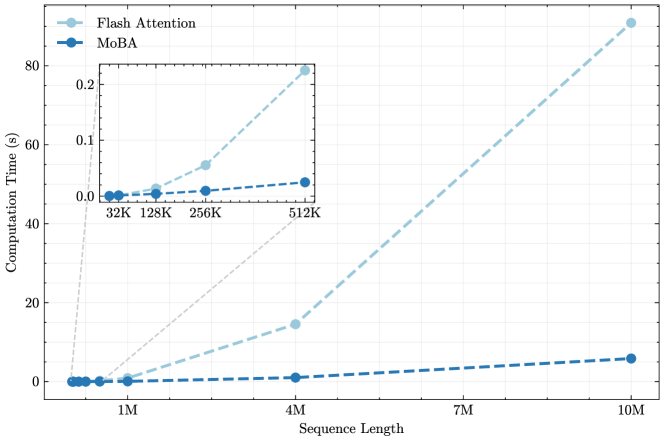
## Line Chart: Computation Time vs. Sequence Length for Flash Attention and MoBA
### Overview
The image is a line chart comparing the computational performance of two methods, "Flash Attention" and "MoBA," as the input sequence length increases. The chart demonstrates a significant performance divergence between the two methods at longer sequence lengths. An inset chart provides a zoomed-in view of the performance for shorter sequences.
### Components/Axes
* **Chart Type:** Line chart with a dashed line style and circular data points.
* **X-Axis (Main Chart):** Labeled "Sequence Length". The scale is linear, with major tick marks at 1M, 4M, 7M, and 10M.
* **Y-Axis (Main Chart):** Labeled "Computation Time (s)". The scale is linear, ranging from 0 to 80 seconds, with major tick marks every 20 seconds.
* **Legend:** Located in the top-left corner of the main chart area.
* **Flash Attention:** Represented by a light blue (`#a6cee3` approximate) dashed line with circular markers.
* **MoBA:** Represented by a dark blue (`#1f78b4` approximate) dashed line with circular markers.
* **Inset Chart:** A smaller chart positioned in the upper-left quadrant of the main chart area. It zooms in on the performance for shorter sequence lengths.
* **X-Axis (Inset):** Labeled with specific sequence lengths: 32K, 128K, 256K, 512K.
* **Y-Axis (Inset):** Unlabeled, but shares the same unit (seconds) as the main chart. The scale ranges from 0.0 to 0.2 seconds.
* **Data Series:** The same two series (Flash Attention and MoBA) are plotted in the inset with the same color and style coding.
### Detailed Analysis
**Main Chart Analysis (Sequence Lengths ~1M to 10M):**
* **Trend Verification - Flash Attention (Light Blue):** The line exhibits a steep, upward, and accelerating (super-linear, likely quadratic or worse) trend.
* At ~1M sequence length, computation time is near 0 seconds (approximately 0.5s).
* At 4M sequence length, computation time is approximately 15 seconds.
* At 10M sequence length, computation time is approximately 90 seconds (the data point is slightly above the 80s grid line).
* **Trend Verification - MoBA (Dark Blue):** The line exhibits a very shallow, near-linear upward trend.
* At ~1M sequence length, computation time is near 0 seconds (approximately 0.1s).
* At 4M sequence length, computation time is approximately 1 second.
* At 10M sequence length, computation time is approximately 5 seconds.
**Inset Chart Analysis (Sequence Lengths 32K to 512K):**
* **Trend Verification - Flash Attention (Light Blue):** Shows a clear upward curve even at these shorter lengths.
* At 32K: ~0.005s
* At 128K: ~0.01s
* At 256K: ~0.05s
* At 512K: ~0.2s
* **Trend Verification - MoBA (Dark Blue):** Shows a very slight, almost flat increase.
* At 32K: ~0.002s
* At 128K: ~0.003s
* At 256K: ~0.005s
* At 512K: ~0.01s
### Key Observations
1. **Performance Crossover:** While both methods have sub-second computation times for sequences under 1M, their performance diverges dramatically thereafter.
2. **Scalability:** MoBA demonstrates vastly superior scalability. Its computation time grows approximately linearly with sequence length. Flash Attention's computation time grows at a much faster, non-linear rate.
3. **Magnitude of Difference:** At the longest measured sequence (10M), Flash Attention is approximately **18 times slower** (90s vs. 5s) than MoBA.
4. **Inset Purpose:** The inset is crucial for visualizing the performance relationship at shorter sequences, where the main chart's scale compresses both lines near zero.
### Interpretation
This chart presents a compelling performance benchmark for sequence processing tasks, likely in the context of transformer-based machine learning models. The data strongly suggests that **MoBA is a more computationally efficient and scalable algorithm than Flash Attention for handling very long sequences.**
* **Underlying Mechanism:** The near-linear scaling of MoBA implies its computational complexity is O(n) or O(n log n) with respect to sequence length (n). The super-linear scaling of Flash Attention suggests a complexity of O(n²) or worse, which becomes prohibitively expensive for long contexts.
* **Practical Implication:** For applications requiring the processing of extremely long documents, high-resolution images, or lengthy videos (where sequence length can reach millions of tokens), MoBA would enable feasible processing where Flash Attention would not. The inset shows this advantage begins even at moderate lengths (512K).
* **Anomaly/Note:** The chart does not specify the hardware or exact task used for benchmarking. The absolute time values are therefore relative, but the *relative performance difference* and *scaling trends* are the key takeaways. The consistent color coding and clear trends make the conclusion robust.