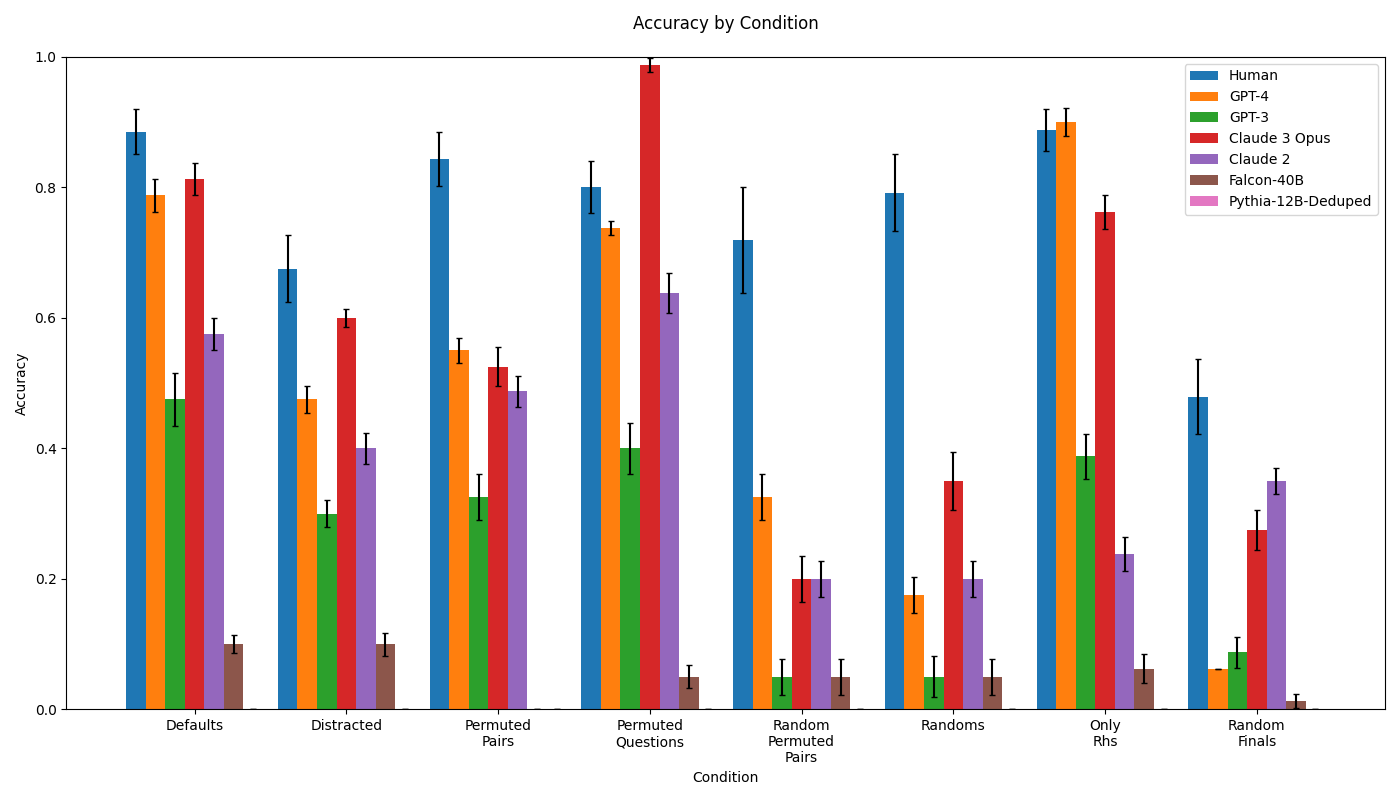
## Bar Chart: Accuracy by Condition
### Overview
The image is a bar chart comparing the accuracy of different AI models (GPT-4, GPT-3, Claude 3 Opus, Claude 2, Falcon-40B, Pythia-12B-Deduped) and humans across various conditions (Defaults, Distracted, Permuted Pairs, Permuted Questions, Random Permuted Pairs, Randoms, Only Rhs, Random Finals). The chart displays accuracy on the y-axis, ranging from 0.0 to 1.0, and the condition on the x-axis. Error bars are included on each bar, indicating the variability in the accuracy measurements.
### Components/Axes
* **Title:** Accuracy by Condition
* **X-axis:** Condition
* Categories: Defaults, Distracted, Permuted Pairs, Permuted Questions, Random Permuted Pairs, Randoms, Only Rhs, Random Finals
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located in the top-right corner.
* Human (Blue)
* GPT-4 (Orange)
* GPT-3 (Green)
* Claude 3 Opus (Red)
* Claude 2 (Purple)
* Falcon-40B (Brown)
* Pythia-12B-Deduped (Pink)
### Detailed Analysis
**Defaults Condition:**
* Human (Blue): Accuracy ~0.88 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.79 +/- 0.04
* GPT-3 (Green): Accuracy ~0.48 +/- 0.05
* Claude 3 Opus (Red): Accuracy ~0.82 +/- 0.04
* Claude 2 (Purple): Accuracy ~0.57 +/- 0.05
* Falcon-40B (Brown): Accuracy ~0.10 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.11 +/- 0.01
**Distracted Condition:**
* Human (Blue): Accuracy ~0.68 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.48 +/- 0.04
* GPT-3 (Green): Accuracy ~0.30 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.60 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.39 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.09 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.10 +/- 0.01
**Permuted Pairs Condition:**
* Human (Blue): Accuracy ~0.84 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.54 +/- 0.04
* GPT-3 (Green): Accuracy ~0.52 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.59 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.49 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.05 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.05 +/- 0.01
**Permuted Questions Condition:**
* Human (Blue): Accuracy ~0.80 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.75 +/- 0.04
* GPT-3 (Green): Accuracy ~0.54 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.99 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.64 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.05 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.05 +/- 0.01
**Random Permuted Pairs Condition:**
* Human (Blue): Accuracy ~0.72 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.33 +/- 0.04
* GPT-3 (Green): Accuracy ~0.05 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.20 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.20 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.07 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.05 +/- 0.01
**Randoms Condition:**
* Human (Blue): Accuracy ~0.80 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.18 +/- 0.04
* GPT-3 (Green): Accuracy ~0.05 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.35 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.05 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.05 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.05 +/- 0.01
**Only Rhs Condition:**
* Human (Blue): Accuracy ~0.89 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.77 +/- 0.04
* GPT-3 (Green): Accuracy ~0.39 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.24 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.25 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.06 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.05 +/- 0.01
**Random Finals Condition:**
* Human (Blue): Accuracy ~0.48 +/- 0.05
* GPT-4 (Orange): Accuracy ~0.07 +/- 0.04
* GPT-3 (Green): Accuracy ~0.09 +/- 0.03
* Claude 3 Opus (Red): Accuracy ~0.28 +/- 0.05
* Claude 2 (Purple): Accuracy ~0.35 +/- 0.04
* Falcon-40B (Brown): Accuracy ~0.05 +/- 0.01
* Pythia-12B-Deduped (Pink): Accuracy ~0.18 +/- 0.01
### Key Observations
* Human accuracy is generally high across all conditions, with the exception of "Random Finals".
* Claude 3 Opus shows the highest accuracy in the "Permuted Questions" condition, reaching nearly 1.0.
* Falcon-40B and Pythia-12B-Deduped consistently show low accuracy across all conditions.
* The accuracy of all models varies significantly depending on the condition.
* The error bars indicate some variability in the accuracy measurements, which should be considered when interpreting the results.
### Interpretation
The bar chart provides a comparative analysis of the accuracy of different AI models and humans under various conditions. The data suggests that the performance of AI models is highly dependent on the specific task or condition. For example, Claude 3 Opus excels in "Permuted Questions," while all models struggle with "Random Finals." The consistently low accuracy of Falcon-40B and Pythia-12B-Deduped suggests that these models may not be well-suited for the tasks represented by these conditions. The variability indicated by the error bars highlights the need for caution when drawing definitive conclusions based on these results. The chart demonstrates the strengths and weaknesses of each model, providing valuable insights for selecting the appropriate model for a given task. The human performance serves as a benchmark, highlighting the gap between current AI capabilities and human-level intelligence in these specific scenarios.