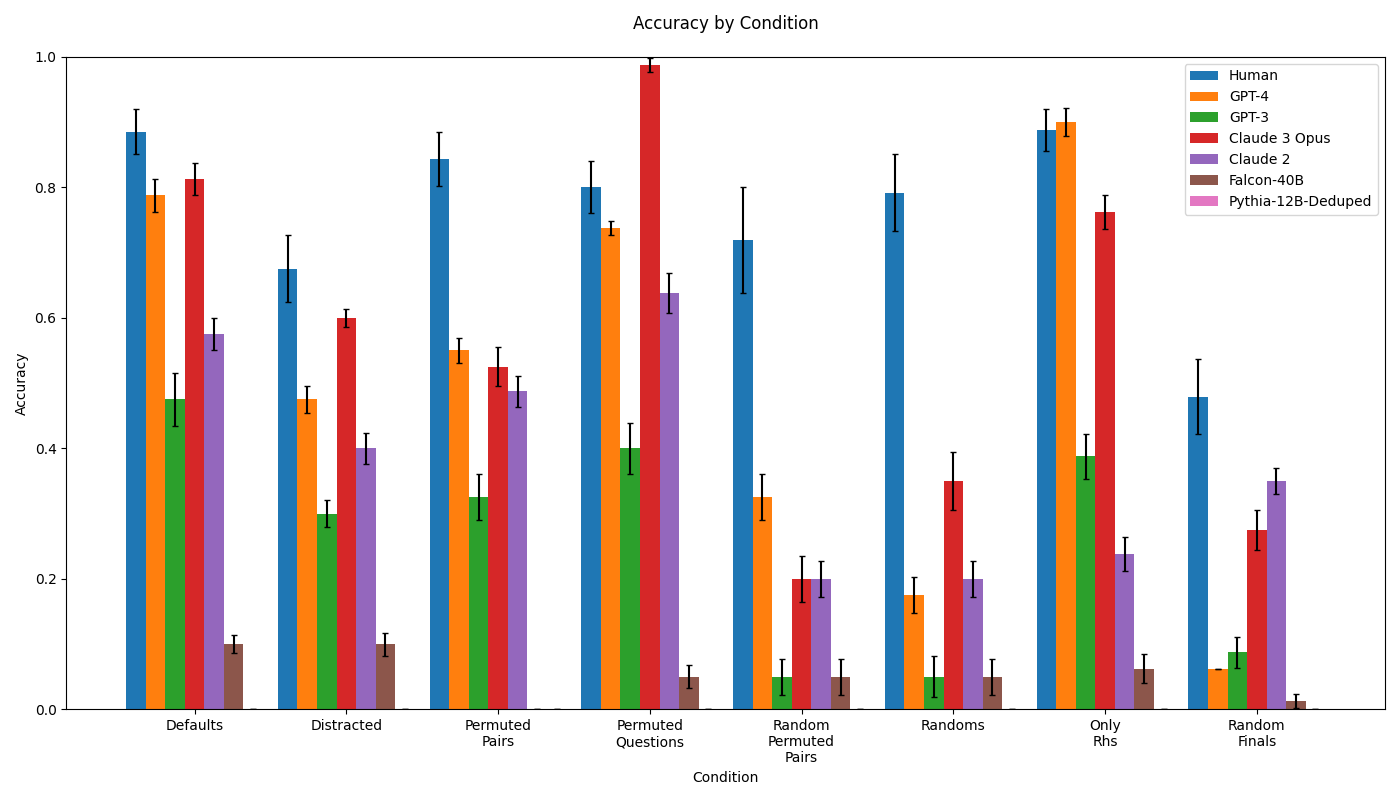
## Bar Chart: Accuracy by Condition
### Overview
The chart compares the accuracy of various AI models and human performance across seven experimental conditions: Defaults, Distracted, Permuted Pairs, Permuted Questions, Random Permuted Pairs, Randoms, Only RHS, and Random Finals. Accuracy values range from 0 to 1, with error bars indicating variability. The legend identifies seven entities: Human, GPT-4, GPT-3, Claude 3 Opus, Claude 2, Falcon-40B, and Pythia-12B-Deduped.
### Components/Axes
- **X-axis (Condition)**: Categorical labels for experimental conditions (e.g., Defaults, Distracted, Permuted Pairs).
- **Y-axis (Accuracy)**: Numerical scale from 0 to 1, representing accuracy percentages.
- **Legend**: Positioned in the top-right corner, mapping colors to entities:
- Blue: Human
- Orange: GPT-4
- Green: GPT-3
- Red: Claude 3 Opus
- Purple: Claude 2
- Brown: Falcon-40B
- Pink: Pythia-12B-Deduped
### Detailed Analysis
1. **Defaults**:
- Human: ~0.88 (±0.05)
- GPT-4: ~0.78 (±0.04)
- Claude 3 Opus: ~0.81 (±0.03)
- Claude 2: ~0.58 (±0.04)
- GPT-3: ~0.48 (±0.03)
- Falcon-40B: ~0.10 (±0.02)
- Pythia-12B-Deduped: Not visible (assumed near 0).
2. **Distracted**:
- Human: ~0.68 (±0.06)
- GPT-4: ~0.48 (±0.05)
- Claude 3 Opus: ~0.60 (±0.04)
- Claude 2: ~0.40 (±0.05)
- GPT-3: ~0.30 (±0.04)
- Falcon-40B: ~0.10 (±0.03)
- Pythia-12B-Deduped: Not visible.
3. **Permuted Pairs**:
- Human: ~0.84 (±0.04)
- GPT-4: ~0.56 (±0.05)
- Claude 3 Opus: ~0.52 (±0.04)
- Claude 2: ~0.48 (±0.05)
- GPT-3: ~0.34 (±0.04)
- Falcon-40B: ~0.05 (±0.02)
- Pythia-12B-Deduped: Not visible.
4. **Permuted Questions**:
- Human: ~0.80 (±0.05)
- GPT-4: ~0.74 (±0.04)
- Claude 3 Opus: ~0.99 (±0.02)
- Claude 2: ~0.64 (±0.05)
- GPT-3: ~0.40 (±0.04)
- Falcon-40B: ~0.05 (±0.02)
- Pythia-12B-Deduped: Not visible.
5. **Random Permuted Pairs**:
- Human: ~0.70 (±0.06)
- GPT-4: ~0.32 (±0.05)
- Claude 3 Opus: ~0.20 (±0.04)
- Claude 2: ~0.20 (±0.05)
- GPT-3: ~0.05 (±0.02)
- Falcon-40B: ~0.05 (±0.02)
- Pythia-12B-Deduped: Not visible.
6. **Randoms**:
- Human: ~0.79 (±0.05)
- GPT-4: ~0.16 (±0.04)
- Claude 3 Opus: ~0.36 (±0.05)
- Claude 2: ~0.20 (±0.05)
- GPT-3: ~0.05 (±0.02)
- Falcon-40B: ~0.05 (±0.02)
- Pythia-12B-Deduped: Not visible.
7. **Only RHS**:
- Human: ~0.88 (±0.04)
- GPT-4: ~0.90 (±0.03)
- Claude 3 Opus: ~0.76 (±0.04)
- Claude 2: ~0.24 (±0.05)
- GPT-3: ~0.39 (±0.04)
- Falcon-40B: ~0.07 (±0.02)
- Pythia-12B-Deduped: Not visible.
8. **Random Finals**:
- Human: ~0.48 (±0.06)
- GPT-4: ~0.06 (±0.03)
- Claude 3 Opus: ~0.28 (±0.05)
- Claude 2: ~0.36 (±0.05)
- GPT-3: ~0.09 (±0.03)
- Falcon-40B: ~0.02 (±0.01)
- Pythia-12B-Deduped: Not visible.
### Key Observations
- **Human Performance**: Consistently highest across all conditions, with minor drops in Distracted (~0.68) and Random Finals (~0.48).
- **Top Models**: GPT-4 and Claude 3 Opus outperform others in most conditions, with Claude 3 Opus achieving near-perfect accuracy (~0.99) in Permuted Questions.
- **Low Performers**: Falcon-40B and Pythia-12B-Deduped show minimal accuracy, often below 0.10, except in Defaults (~0.10 for Falcon-40B).
- **Error Bars**: Largest variability in Distracted (~±0.06 for Human) and Randoms (~±0.05 for GPT-4), suggesting sensitivity to noise.
### Interpretation
The data demonstrates that humans and advanced AI models (GPT-4, Claude 3 Opus) maintain robust accuracy across diverse conditions, with humans excelling in complex scenarios like Permuted Questions. However, all models struggle with randomness (Randoms, Random Finals), where accuracy drops sharply. The near-perfect performance of Claude 3 Opus in Permuted Questions suggests specialized training for structured tasks. Lower-performing models (Falcon-40B, Pythia-12B-Deduped) likely lack the capacity to handle non-default conditions, highlighting limitations in generalization. The error bars indicate that variability increases in challenging conditions, emphasizing the need for error-aware evaluations in real-world applications.