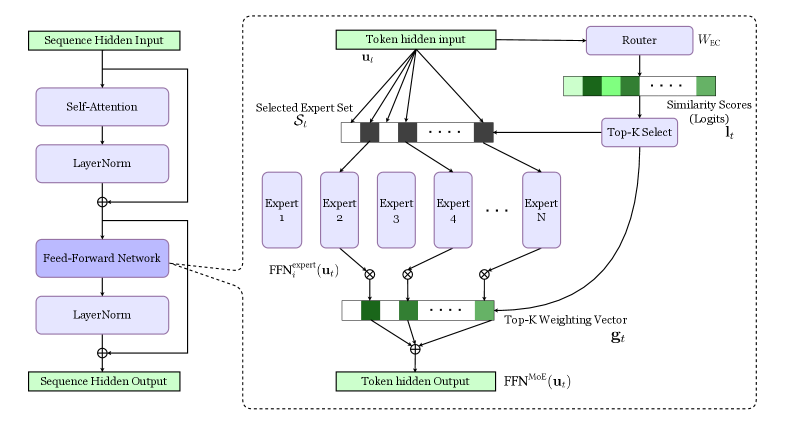
## Diagram: Mixture of Experts (MoE) Neural Network Architecture
### Overview
The diagram illustrates a hybrid neural network architecture combining standard Transformer components with a Mixture of Experts (MoE) mechanism. The left side shows a standard Transformer block, while the right side details the MoE routing and expert selection process.
### Components/Axes
**Left Side (Standard Transformer Block):**
- **Sequence Hidden Input** → **Self-Attention** → **LayerNorm** → **Feed-Forward Network (FFN)** → **LayerNorm** → **Sequence Hidden Output**
- Key components: Self-Attention, LayerNorm, FFN
**Right Side (MoE Mechanism):**
- **Token hidden input** → **Router** (weights: _W<sub>EC</sub>_) → **Top-K Select** (logits: _l<sub>t</sub>_) → **Selected Expert Set** (Experts 1–N)
- **FFN<sup>expert</sup>**(_u<sub>t</sub>_) → **Top-K Weighting Vector** (_g<sub>t</sub>_) → **FFN<sup>MoE</sup>**(_u<sub>t</sub>_) → **Token hidden Output**
**Key Elements:**
- Router weights: _W<sub>EC</sub>_
- Similarity scores: Logits (_l<sub>t</sub>_)
- Expert selection: Top-K mechanism
- Expert outputs: Combined via weighting vector _g<sub>t</sub>_
### Detailed Analysis
1. **Standard Transformer Flow:**
- Input sequence undergoes self-attention and layer normalization
- Feed-forward network processes the output
- Final layer normalization produces sequence-level hidden states
2. **MoE Mechanism:**
- Token-level input (_u<sub>t</sub>_) is routed through a learned weight matrix _W<sub>EC</sub>_
- Router computes similarity scores (logits _l<sub>t</sub>_) for all experts
- Top-K experts are selected based on highest logits
- Selected experts process the input independently
- Final output combines expert results using a Top-K weighting vector _g<sub>t</sub>_
3. **Mathematical Notation:**
- Expert-specific FFN: FFN<sup>expert</sup>(_u<sub>t</sub>_)
- MoE-combined FFN: FFN<sup>MoE</sup>(_u<sub>t</sub>_)
- Weighting vector: _g<sub>t</sub>_ (Top-K experts)
### Key Observations
- **Dynamic Expert Selection:** Each token independently selects experts based on similarity scores
- **Expert Specialization:** N distinct experts handle different input patterns
- **Efficiency:** Only K experts are activated per token (K << N)
- **Integration:** MoE output merges with standard Transformer processing
### Interpretation
This architecture demonstrates a hybrid approach to neural network design:
1. **Specialization vs. Generality:** Standard Transformer components handle general sequence processing, while MoE experts specialize in specific input patterns
2. **Efficiency Gains:** By activating only K experts per token, the model reduces computational load compared to using all N experts
3. **Adaptive Routing:** The router's learned weights _W<sub>EC</sub>_ enable dynamic adaptation to input characteristics
4. **Performance Tradeoff:** The Top-K selection balances expert diversity with computational constraints
The diagram suggests this architecture could achieve state-of-the-art performance on complex tasks while maintaining computational efficiency through expert specialization and sparse activation.