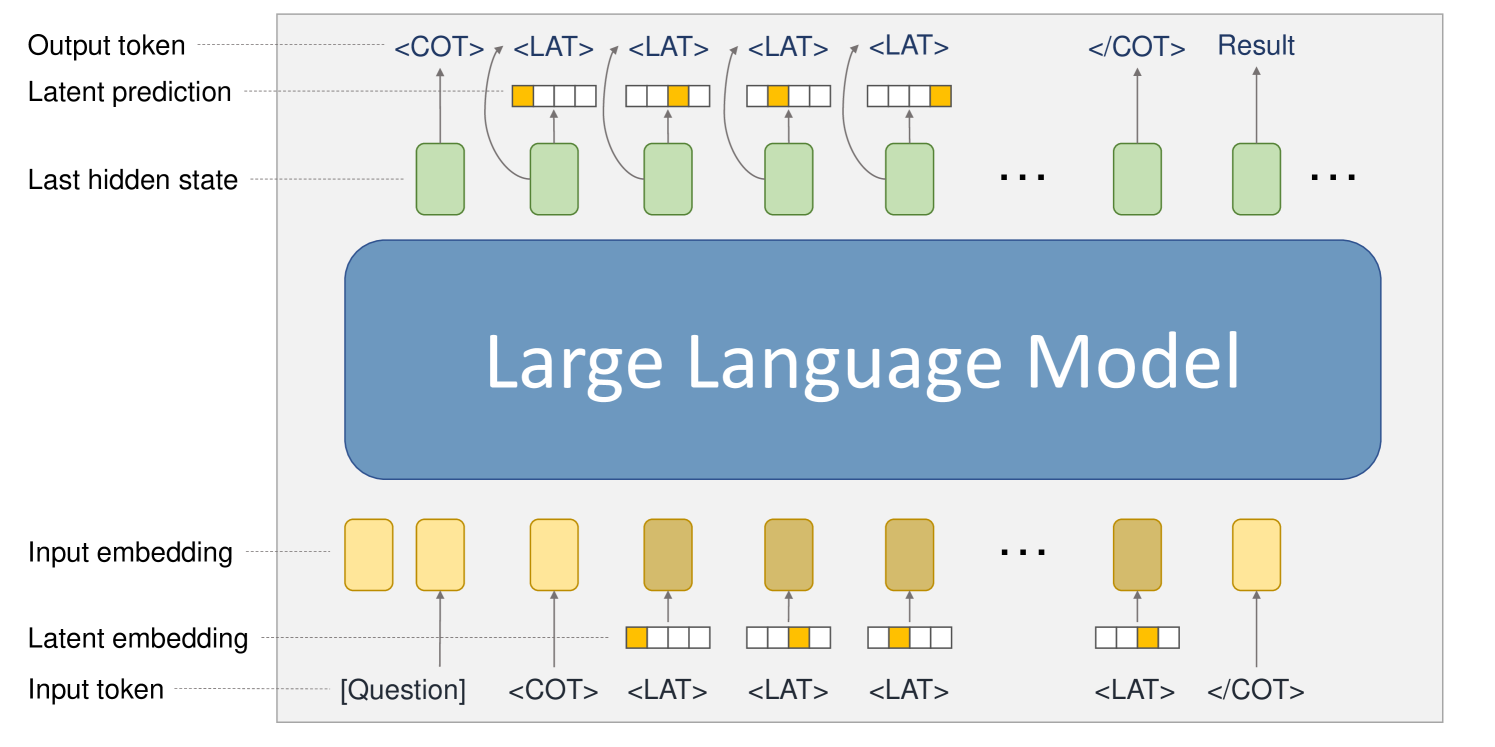
## Diagram: Large Language Model Processing Flow
### Overview
The diagram illustrates the sequential processing flow of a large language model (LLM), showing how input tokens are transformed into output tokens through multiple stages. It emphasizes latent embeddings, hidden states, and prediction mechanisms.
### Components/Axes
1. **Input Section**:
- **Input Token**: Labeled as `[Question]` (yellow rectangle).
- **Tokens**: Includes `<COT>` (Chain-of-Thought start) and repeated `<LAT>` (Latent) tokens.
- **Input Embedding**: Yellow rectangles representing token embeddings.
2. **Latent Processing**:
- **Latent Embedding**: Brown rectangles with yellow highlights, showing token-specific latent representations.
- **Latent Prediction**: Green rectangles indicating model predictions at each stage.
3. **Model Core**:
- **Large Language Model**: Central blue rectangle labeled "Large Language Model," acting as the processing engine.
4. **Output Section**:
- **Last Hidden State**: Green rectangles representing the model's internal state after processing.
- **Output Token**: Includes `<COT>` and `<LAT>` tokens, with the final token labeled `Result`.
- **Flow Arrows**: Indicate sequential processing from input to output.
### Detailed Analysis
- **Input Tokenization**: The input starts with a question token (`[Question]`), followed by `<COT>` and multiple `<LAT>` tokens, suggesting a structured prompt for reasoning.
- **Embedding Layers**: Input tokens are first converted into embeddings (yellow), then refined into latent embeddings (brown with yellow highlights), capturing semantic and contextual features.
- **Model Processing**: The LLM processes latent embeddings, generating latent predictions (green) at each step. These predictions are tied to the `<LAT>` tokens, indicating iterative reasoning.
- **Output Generation**: The final output combines the last hidden state (green) with latent predictions to produce the `Result`, ending with `<COT>` to close the reasoning chain.
### Key Observations
1. **Sequential Reasoning**: The repeated `<LAT>` tokens and their corresponding latent predictions suggest the model performs step-by-step reasoning, typical of chain-of-thought (CoT) prompting.
2. **Latent State Integration**: The last hidden state (green) is critical for generating the final output, highlighting the model's reliance on internal memory.
3. **Token-Specific Processing**: Latent embeddings (brown) are visually distinct, emphasizing their role in capturing token-level nuances.
### Interpretation
The diagram demonstrates how LLMs handle complex tasks by breaking them into latent steps. The use of `<COT>` and `<LAT>` tokens indicates a structured approach to reasoning, where the model generates intermediate predictions before arriving at the final result. The color-coded components (yellow for input, brown for latent, green for predictions) visually separate stages, aiding in understanding the model's architecture. This flow underscores the importance of latent representations and hidden states in enabling coherent, multi-step reasoning in LLMs.