# Technical Document Extraction: Attention Forward Speed Benchmark
## 1. Metadata and Header Information
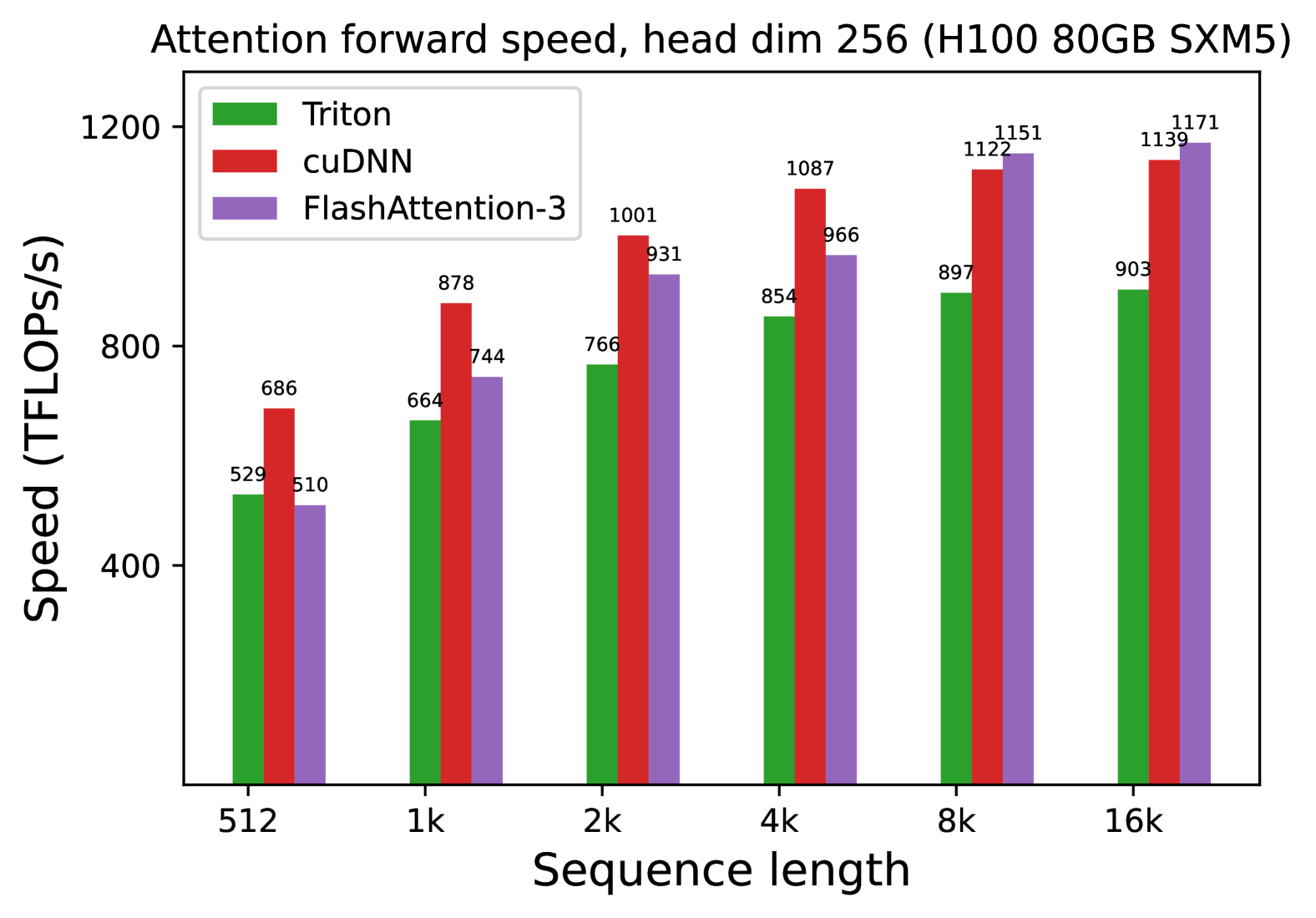
* **Title:** Attention forward speed, head dim 256 (H100 80GB SXM5)
* **Hardware Context:** NVIDIA H100 80GB SXM5 GPU.
* **Metric:** Speed measured in TFLOPS/s (Tera Floating Point Operations Per Second).
* **Primary Variable:** Sequence length (x-axis).
## 2. Component Isolation
### A. Legend
The legend identifies three distinct software implementations:
* **Green Bar:** Triton
* **Red Bar:** cuDNN
* **Purple Bar:** FlashAttention-3
### B. Axis Definitions
* **Y-Axis (Vertical):** Speed (TFLOPS/s). Scale ranges from 400 to 1200 with major tick marks at 400, 800, and 1200.
* **X-Axis (Horizontal):** Sequence length. Categories are: 512, 1k, 2k, 4k, 8k, 16k.
## 3. Data Extraction and Trend Analysis
### Trend Verification
* **Triton (Green):** Shows a consistent upward slope as sequence length increases, beginning to plateau between 8k and 16k.
* **cuDNN (Red):** Shows a strong upward slope, peaking at 8k and maintaining high performance at 16k. It is the fastest implementation for sequence lengths between 512 and 4k.
* **FlashAttention-3 (Purple):** Shows the steepest growth curve. While it starts as the slowest at 512, it overtakes Triton at 2k and overtakes cuDNN at 8k, becoming the fastest implementation for the longest sequence lengths (8k-16k).
### Data Table (Reconstructed)
| Sequence Length | Triton (Green) | cuDNN (Red) | FlashAttention-3 (Purple) |
| :--- | :--- | :--- | :--- |
| **512** | 529 | 686 | 510 |
| **1k** | 664 | 878 | 744 |
| **2k** | 766 | 1001 | 931 |
| **4k** | 854 | 1087 | 966 |
| **8k** | 897 | 1122 | 1151 |
| **16k** | 903 | 1139 | 1171 |
## 4. Key Findings and Observations
* **Peak Performance:** The highest recorded value is **1171 TFLOPS/s**, achieved by **FlashAttention-3** at a sequence length of 16k.
* **Crossover Point:** FlashAttention-3 demonstrates superior scaling. It surpasses cuDNN's performance once the sequence length reaches 8k.
* **Efficiency:** All three methods show significant performance gains as sequence length increases from 512 to 4k, likely due to better hardware utilization on the H100 GPU at larger scales.
* **Relative Performance:** At the smallest sequence length (512), cuDNN is ~34% faster than FlashAttention-3. At the largest sequence length (16k), FlashAttention-3 is ~2.8% faster than cuDNN and ~29.6% faster than Triton.