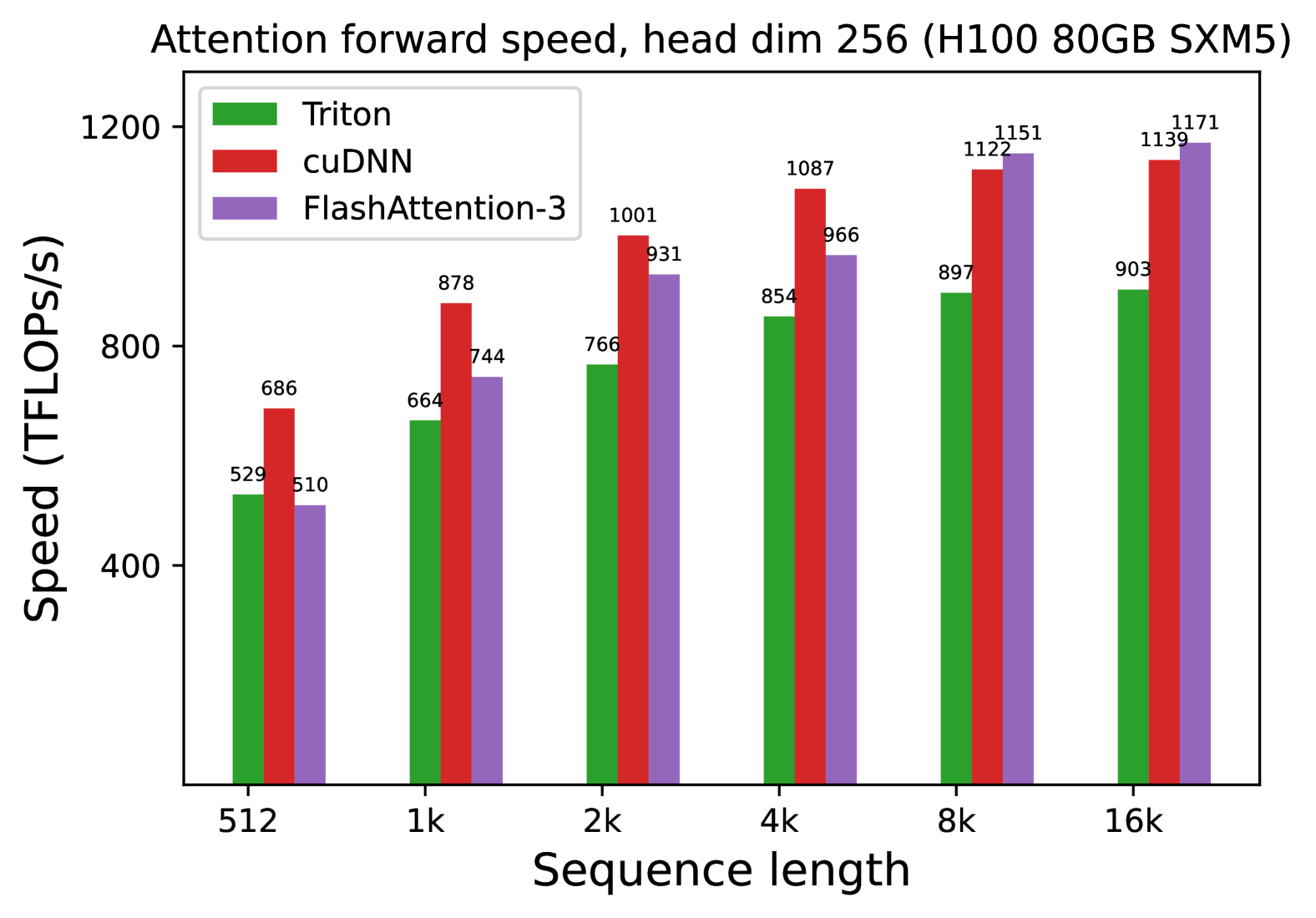
# Technical Document Extraction: Attention Forward Speed Analysis
## Chart Title
**Attention forward speed, head dim 256 (H100 80GB SXM5)**
## Axis Labels
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
## Legend
- **Triton**: Green
- **cuDNN**: Red
- **FlashAttention-3**: Purple
## Data Points (Speed in TFLOPs/s)
| Sequence Length | Triton | cuDNN | FlashAttention-3 |
|-----------------|--------|-------|------------------|
| 512 | 529 | 686 | 510 |
| 1k | 664 | 878 | 744 |
| 2k | 766 | 1001 | 931 |
| 4k | 854 | 1087 | 966 |
| 8k | 897 | 1122 | 1151 |
| 16k | 903 | 1139 | 1171 |
## Key Trends
1. **Triton**:
- Consistently the lowest performer across all sequence lengths.
- Speed increases linearly with sequence length (e.g., 529 → 903 TFLOPs/s from 512 → 16k).
2. **cuDNN**:
- Dominates performance at shorter sequence lengths (e.g., 686 TFLOPs/s at 512).
- Maintains highest speed until 16k, where FlashAttention-3 surpasses it by 32 TFLOPs/s.
3. **FlashAttention-3**:
- Outperforms Triton at all lengths but trails cuDNN until 16k.
- Shows steepest improvement with longer sequences (e.g., +427 TFLOPs/s from 512 → 16k).
## Hardware Context
- GPU: H100 80GB SXM5
- Head dimension: 256