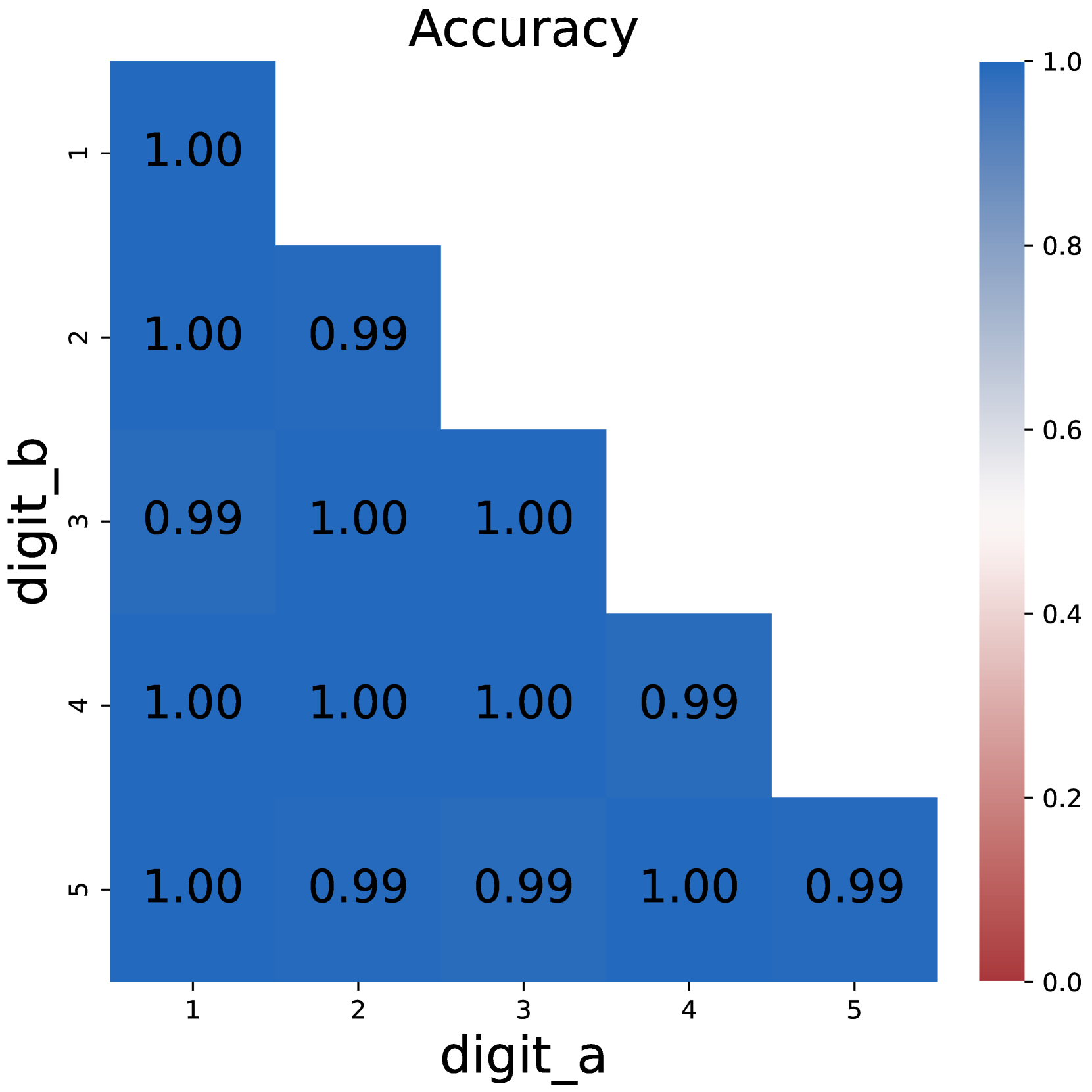
## Heatmap: Accuracy Matrix for Digit Recognition
### Overview
The image is a square heatmap titled "Accuracy," visualizing the performance of a digit recognition system. The matrix compares predicted digits (`digit_a`) against true digits (`digit_b`), with values ranging from 0.00 (red) to 1.00 (blue) on a color gradient scale. The matrix is 5x5, with axes labeled `digit_a` (horizontal) and `digit_b` (vertical), both ranging from 1 to 5.
### Components/Axes
- **Title**: "Accuracy"
- **X-axis (digit_a)**: Labeled "digit_a," with categories 1–5.
- **Y-axis (digit_b)**: Labeled "digit_b," with categories 1–5.
- **Legend**: Positioned on the right, with a gradient from red (0.0) to blue (1.0).
- **Cell Values**: Numerical accuracy scores embedded in each cell (e.g., 1.00, 0.99).
### Detailed Analysis
- **Diagonal Cells (digit_a = digit_b)**: All values are **1.00**, indicating perfect accuracy when the predicted digit matches the true digit.
- **Off-Diagonal Cells (digit_a ≠ digit_b)**: Most values are **0.99**, with a few exceptions (e.g., `digit_a=2` vs. `digit_b=1` and `digit_a=5` vs. `digit_b=3` also show 0.99). These represent near-perfect accuracy for mismatched digits.
- **Color Consistency**: Blue dominates the matrix, aligning with the legend’s high-accuracy range. Red is absent, confirming no cells fall below 0.99.
### Key Observations
1. **Perfect Diagonal Accuracy**: The diagonal (1.00) confirms the system flawlessly identifies correct digits.
2. **High Off-Diagonal Accuracy**: Off-diagonal values (0.99) suggest minimal confusion between digits, even when mismatched.
3. **Uniformity**: All non-diagonal cells share the same value (0.99), indicating consistent performance across digit pairs.
### Interpretation
This heatmap demonstrates a highly accurate digit recognition system. The perfect diagonal (1.00) reflects no errors in identifying correct digits. The near-perfect off-diagonal values (0.99) imply the system rarely confuses digits, even when predictions are incorrect. The uniformity of off-diagonal values suggests the model’s errors are not concentrated in specific digit pairs but are broadly distributed. This could indicate a robust model with minor, systematic limitations in distinguishing certain digit combinations. The absence of red cells (0.00) confirms no complete failures in digit recognition.