## Bar Chart: Avg. Coherence Scores
### Overview
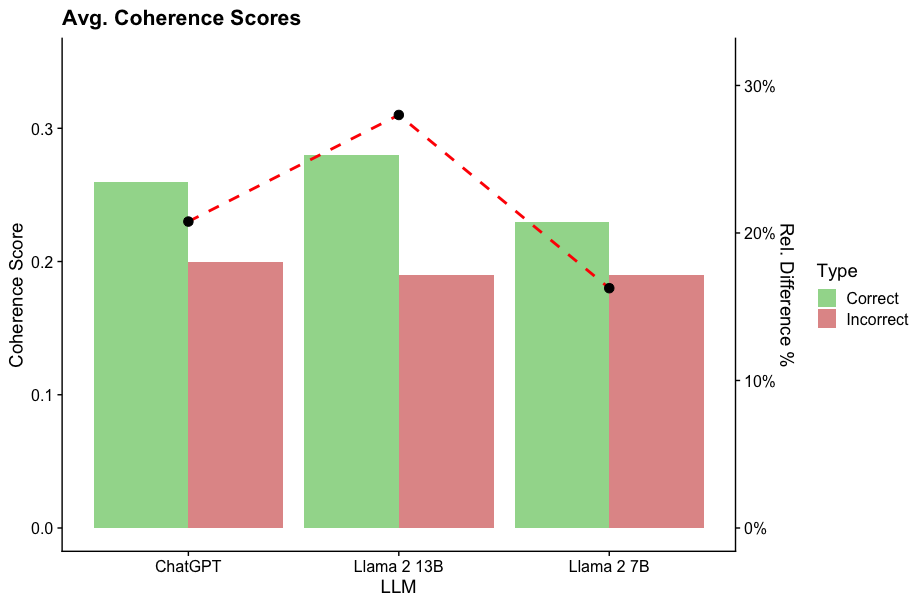
The image is a bar chart comparing the average coherence scores of three Large Language Models (LLMs): ChatGPT, Llama 2 13B, and Llama 2 7B. The chart displays coherence scores for both "Correct" and "Incorrect" types, represented by green and red bars, respectively. A secondary y-axis shows the relative difference percentage, plotted as a dashed red line with black circular markers.
### Components/Axes
* **Title:** Avg. Coherence Scores
* **X-axis:** LLM (ChatGPT, Llama 2 13B, Llama 2 7B)
* **Left Y-axis:** Coherence Score (scale from 0.0 to 0.3, with increments of 0.1)
* **Right Y-axis:** Rel. Difference % (scale from 0% to 30%, with increments of 10%)
* **Legend:** Located on the right side of the chart.
* Correct (Green)
* Incorrect (Red)
### Detailed Analysis
* **ChatGPT:**
* Correct: Coherence score is approximately 0.25.
* Incorrect: Coherence score is approximately 0.20.
* Relative Difference: Approximately 23%.
* **Llama 2 13B:**
* Correct: Coherence score is approximately 0.28.
* Incorrect: Coherence score is approximately 0.19.
* Relative Difference: Approximately 31%.
* **Llama 2 7B:**
* Correct: Coherence score is approximately 0.23.
* Incorrect: Coherence score is approximately 0.19.
* Relative Difference: Approximately 18%.
* **Relative Difference Trend:** The red dashed line shows the relative difference percentage. It starts at approximately 23% for ChatGPT, increases to approximately 31% for Llama 2 13B, and then decreases to approximately 18% for Llama 2 7B.
### Key Observations
* For all three LLMs, the coherence score for "Correct" type is higher than the coherence score for "Incorrect" type.
* Llama 2 13B has the highest coherence score for "Correct" type and the highest relative difference percentage.
* Llama 2 7B has the lowest coherence score for "Correct" type and the lowest relative difference percentage.
* The "Incorrect" coherence scores are relatively similar across all three LLMs, ranging from approximately 0.19 to 0.20.
### Interpretation
The chart suggests that Llama 2 13B performs the best in terms of coherence score when the model's output is correct. The relative difference percentage indicates the degree to which the coherence score differs between correct and incorrect outputs. A higher percentage suggests a greater disparity in coherence between correct and incorrect outputs. The data indicates that while all models perform better on "Correct" outputs, Llama 2 13B exhibits the most significant difference in coherence between correct and incorrect outputs. ChatGPT and Llama 2 7B show relatively similar performance, with Llama 2 7B having a slightly lower relative difference percentage.