\n
## Bar Chart: Avg. Coherence Scores
### Overview
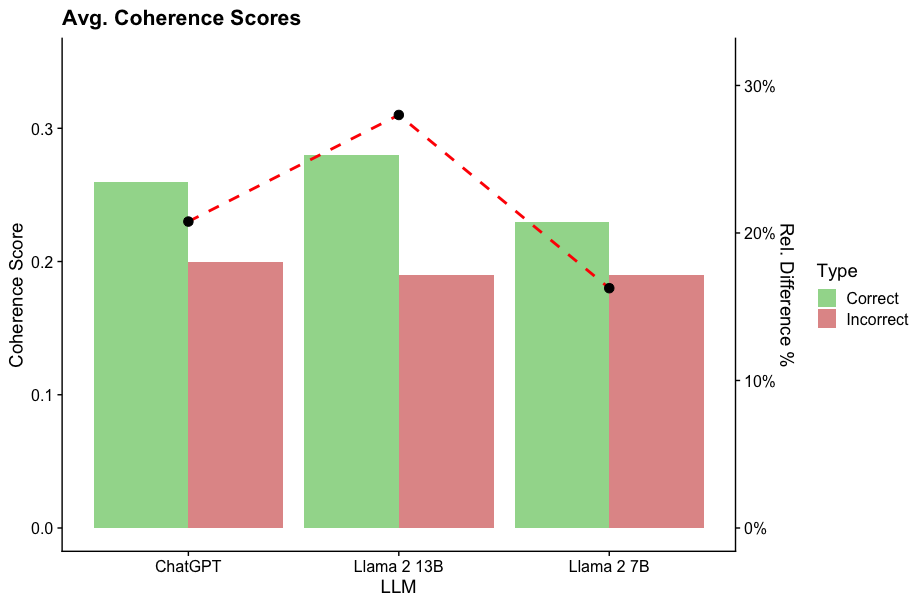
This bar chart compares the average coherence scores of three Large Language Models (LLMs): ChatGPT, Llama 2 13B, and Llama 2 7B. It presents both the coherence score itself (as a bar height) and the relative difference (%) between correct and incorrect responses (as a red dashed line with markers). A secondary y-axis on the right displays the percentage scale for the relative difference.
### Components/Axes
* **Title:** Avg. Coherence Scores
* **X-axis Label:** LLM (with categories: ChatGPT, Llama 2 13B, Llama 2 7B)
* **Y-axis Label (left):** Coherence Score (scale from 0.0 to 0.3)
* **Y-axis Label (right):** Rel. Difference % (scale from 0% to 30%)
* **Legend:** Located in the top-right corner.
* **Type:** Correct (represented by green bars)
* **Type:** Incorrect (represented by red bars)
* **Data Series:**
* Correct Coherence Score (Green Bars)
* Incorrect Coherence Score (Red Bars)
* Relative Difference (%) (Red Dashed Line with Markers)
### Detailed Analysis
The chart displays three sets of bars, one for each LLM, representing the coherence scores for correct and incorrect responses. A red dashed line connects markers indicating the relative difference between correct and incorrect responses for each LLM.
* **ChatGPT:**
* Correct Coherence Score: Approximately 0.26 (±0.01)
* Incorrect Coherence Score: Approximately 0.22 (±0.01)
* Relative Difference: Approximately 24% (±2%)
* **Llama 2 13B:**
* Correct Coherence Score: Approximately 0.31 (±0.01)
* Incorrect Coherence Score: Approximately 0.28 (±0.01)
* Relative Difference: Approximately 31% (±2%)
* **Llama 2 7B:**
* Correct Coherence Score: Approximately 0.24 (±0.01)
* Incorrect Coherence Score: Approximately 0.18 (±0.01)
* Relative Difference: Approximately 20% (±2%)
The red dashed line shows a trend: it starts at approximately 24% for ChatGPT, peaks at approximately 31% for Llama 2 13B, and then decreases to approximately 20% for Llama 2 7B.
### Key Observations
* Llama 2 13B exhibits the highest average coherence score for correct responses.
* Llama 2 13B also has the largest relative difference between correct and incorrect responses, suggesting it is better at distinguishing between coherent and incoherent outputs.
* ChatGPT has a relatively low relative difference compared to Llama 2 13B, indicating a smaller gap in coherence between correct and incorrect responses.
* Llama 2 7B has the lowest coherence score for correct responses and the smallest relative difference.
### Interpretation
The data suggests that Llama 2 13B performs best in terms of generating coherent responses and differentiating them from incoherent ones. ChatGPT shows reasonable coherence but a smaller margin between correct and incorrect outputs. Llama 2 7B appears to struggle with coherence, exhibiting the lowest scores overall.
The relative difference metric is crucial. A higher relative difference indicates that the LLM is more reliable in identifying and producing coherent text. The peak at Llama 2 13B suggests that this model is particularly adept at maintaining coherence. The decreasing trend for Llama 2 7B could indicate that reducing model size (from 13B to 7B parameters) negatively impacts its ability to generate and assess coherence.
The chart provides a comparative assessment of the LLMs' ability to produce meaningful and consistent text, which is a critical aspect of their overall performance. The data could be used to inform model selection for applications requiring high levels of coherence, such as content generation or dialogue systems.