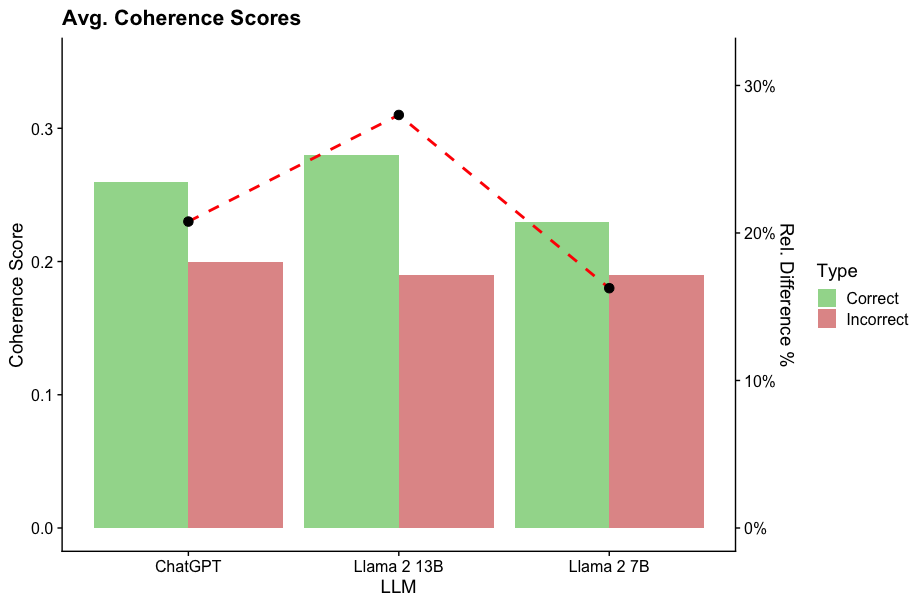
## Bar Chart: Avg. Coherence Scores
### Overview
The chart compares average coherence scores for three language models (ChatGPT, Llama 2 13B, Llama 2 7B) across two categories: "Correct" and "Incorrect" responses. A red dashed line labeled "Rel. Difference %" overlays the chart, showing relative differences between correct and incorrect scores.
### Components/Axes
- **X-axis**: Language models (ChatGPT, Llama 2 13B, Llama 2 7B)
- **Y-axis (left)**: Coherence Score (0.0 to 0.35)
- **Legend (right)**:
- Green = Correct
- Red = Incorrect
- **Secondary Y-axis (right)**: Rel. Difference % (0% to 30%)
### Detailed Analysis
1. **ChatGPT**:
- Correct: ~0.26
- Incorrect: ~0.20
- Relative Difference: ~20% (red dashed line starts here)
2. **Llama 2 13B**:
- Correct: ~0.28
- Incorrect: ~0.19
- Relative Difference: ~30% (peak of red dashed line)
3. **Llama 2 7B**:
- Correct: ~0.22
- Incorrect: ~0.19
- Relative Difference: ~10% (red dashed line dips here)
### Key Observations
- Llama 2 13B has the highest coherence scores for both correct and incorrect responses.
- The relative difference between correct and incorrect scores is largest for Llama 2 13B (30%) and smallest for Llama 2 7B (10%).
- ChatGPT shows a moderate relative difference (20%) with higher incorrect scores than Llama 2 7B.
### Interpretation
The data suggests that Llama 2 13B demonstrates the strongest performance in coherence, with the largest gap between correct and incorrect responses. Llama 2 7B underperforms in both metrics, while ChatGPT balances moderate coherence with a significant relative difference. The red dashed line emphasizes that Llama 2 13B's superiority is most pronounced in the relative difference metric, indicating it handles correct responses more effectively than the others. The consistent incorrect scores across models (~0.19–0.20) suggest similar error rates, but Llama 2 13B's higher correct scores amplify its relative advantage.