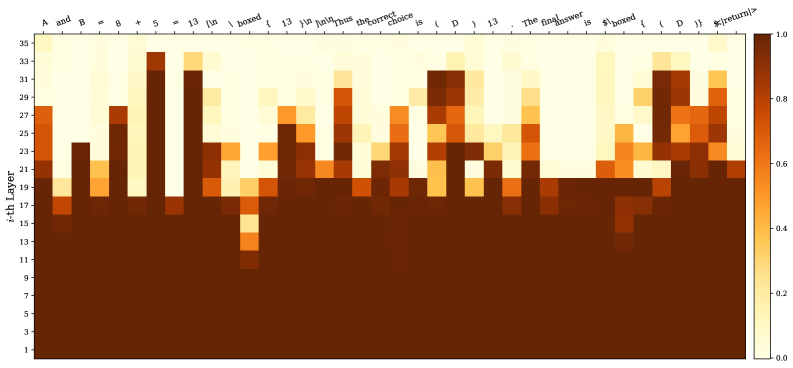
## Heatmap: Layer Activation for Mathematical Expression
### Overview
The image is a heatmap visualizing the activation levels of different layers in a neural network when processing a mathematical expression. The x-axis represents the tokens of the expression, and the y-axis represents the layer number. The color intensity indicates the activation level, ranging from dark brown (low activation) to light yellow (high activation).
### Components/Axes
* **X-axis:** Represents the tokens of the mathematical expression: "A and B = 8 + 5 = 13 \textbackslash n \textbackslash boxed { 13 } \textbackslash n \textbackslash n Thus the correct choice is ( D ) 13 . The final answer is \textbackslash boxed { ( D ) } \$\textbackslash <return/\>".
* **Y-axis:** Represents the layer number, labeled as "i-th Layer", ranging from 1 to 35 in increments of 2.
* **Colorbar:** Located on the right side, indicates the activation level, ranging from 0.0 (dark brown) to 1.0 (light yellow).
### Detailed Analysis
The heatmap shows the activation levels for each layer in response to each token in the input sequence.
* **Layer Activation Distribution:**
* Layers 1 to approximately 17 show consistently high activation (dark brown) across all tokens.
* Above layer 17, the activation patterns become more differentiated, with specific tokens triggering higher activation in certain layers.
* **Token-Specific Activation:**
* The tokens "A", "and", "B", "=", "8", "+", "5", "=", "13", "\textbackslash n", "\textbackslash boxed", "{", "13", "}", "\textbackslash n", "\textbackslash n", "Thus", "the", "correct", "choice", "is", "(", "D", ")", "13", ".", "The", "final", "answer", "is", "\textbackslash boxed", "{", "(", "D", ")", "}", "\$\textbackslash <return/\>" exhibit varying degrees of activation across the upper layers (above layer 17).
* The tokens "8", "+", "5", "13", and "D" show relatively high activation in some of the upper layers.
* The tokens "\textbackslash n", "\textbackslash boxed", "{", "}", ".", and "\$\textbackslash <return/\>" also show distinct activation patterns.
* **Specific Layer Activation:**
* Layers around 27-35 show higher activation for tokens related to the final answer and formatting (e.g., "\textbackslash boxed", "D", "\$\textbackslash <return/\>").
* Layers around 21-25 show higher activation for tokens related to the mathematical operation (e.g., "8", "+", "5", "13").
### Key Observations
* Lower layers (1-17) have consistently high activation, suggesting they might be responsible for basic feature extraction.
* Upper layers (above 17) show more specific activation patterns, indicating they are involved in higher-level reasoning or decision-making.
* The activation patterns vary significantly depending on the token, suggesting that different layers are responsible for processing different types of information.
### Interpretation
The heatmap provides insights into how a neural network processes a mathematical expression. The lower layers seem to handle fundamental feature extraction, while the upper layers focus on more complex tasks like understanding the mathematical operations, formatting the output, and generating the final answer. The varying activation patterns for different tokens highlight the network's ability to differentiate and process various components of the input sequence. The high activation in the upper layers for tokens related to the final answer suggests that these layers are crucial for generating the correct output.