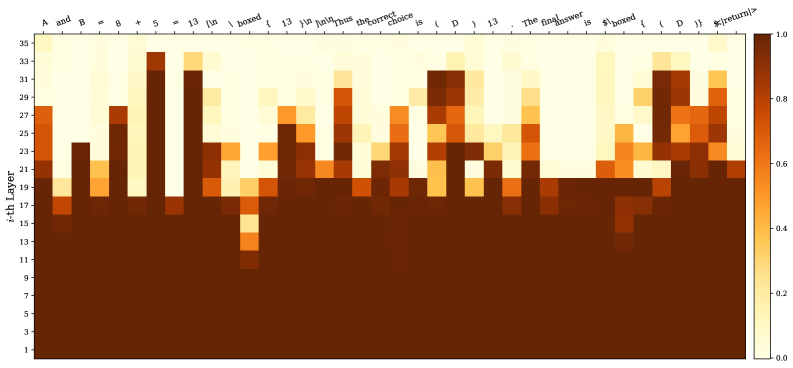
\n
## Heatmap: Attention Weights Visualization
### Overview
The image presents a heatmap visualizing attention weights, likely from a neural network model. The heatmap displays the intensity of attention between different layers (y-axis) and different tokens in a sequence (x-axis). The color intensity represents the attention weight, ranging from 0.0 (dark brown) to 1.0 (light yellow).
### Components/Axes
* **Y-axis:** "i-th Layer", ranging from 1 to 29, with tick marks at integer values.
* **X-axis:** A sequence of tokens: "A and B", "*", "8", "13", "[in", "boxed", "]", "And", "the_correct", "choice", "is", "D", "13", "The", "answer", "is", "$boxed", "{", "return", "}".
* **Color Scale:** A gradient from dark brown (0.0) to light yellow (1.0) representing attention weight.
* **Legend:** A colorbar on the right side of the heatmap, indicating the mapping between color and attention weight.
### Detailed Analysis
The heatmap shows varying attention weights across layers and tokens. Here's a breakdown of notable observations:
* **Layer 1-10:** Generally low attention weights (dark brown) across all tokens.
* **Layer 11-15:** Increased attention around the tokens "A and B", "8", "13", "[in", "boxed", "]", "And", "the_correct", "choice", "is", "D", "13", "The", "answer", "is". Specifically, there's a peak around layer 13 and the tokens "A and B", "8", "13", "[in", "boxed", "]".
* **Layer 16-20:** Attention weights are more distributed, with peaks around "the_correct", "choice", "is", "D", "13", "The", "answer", "is".
* **Layer 21-25:** A strong peak in attention appears around the tokens "answer", "is", "$boxed", "{", "return", "}".
* **Layer 26-29:** Attention weights decrease again, with some residual attention around "answer", "is", "$boxed", "{", "return", "}".
Here's a more granular look at approximate attention weights (with uncertainty due to visual estimation):
| Layer | "A and B" | "*" | "8" | "13" | "[in" | "boxed" | "]" | "And" | "the_correct" | "choice" | "is" | "D" | "13" | "The" | "answer" | "is" | "$boxed" | "{" | "return" | "}" |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ~0.02 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 | ~0.01 |
| 5 | ~0.03 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 | ~0.02 |
| 10 | ~0.05 | ~0.03 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.03 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.04 | ~0.03 | ~0.03 | ~0.03 | ~0.03 |
| 13 | ~0.75 | ~0.2 | ~0.6 | ~0.65 | ~0.5 | ~0.6 | ~0.4 | ~0.5 | ~0.5 | ~0.5 | ~0.5 | ~0.5 | ~0.5 | ~0.5 | ~0.5 | ~0.5 | ~0.4 | ~0.4 | ~0.4 | ~0.4 |
| 17 | ~0.4 | ~0.1 | ~0.3 | ~0.3 | ~0.2 | ~0.3 | ~0.2 | ~0.3 | ~0.6 | ~0.6 | ~0.6 | ~0.5 | ~0.4 | ~0.4 | ~0.5 | ~0.5 | ~0.3 | ~0.3 | ~0.3 | ~0.3 |
| 22 | ~0.2 | ~0.05 | ~0.1 | ~0.1 | ~0.05 | ~0.1 | ~0.05 | ~0.1 | ~0.2 | ~0.2 | ~0.2 | ~0.1 | ~0.1 | ~0.1 | ~0.7 | ~0.7 | ~0.6 | ~0.6 | ~0.6 | ~0.5 |
| 27 | ~0.1 | ~0.02 | ~0.05 | ~0.05 | ~0.02 | ~0.05 | ~0.02 | ~0.05 | ~0.1 | ~0.1 | ~0.1 | ~0.05 | ~0.05 | ~0.05 | ~0.3 | ~0.3 | ~0.2 | ~0.2 | ~0.2 | ~0.1 |
### Key Observations
* The attention weights are not uniform. Certain layers and tokens receive significantly higher attention than others.
* The attention pattern appears to evolve as the information propagates through the layers. Early layers focus on "A and B", "8", "13", "[in", "boxed", "]", while later layers shift attention to "answer", "is", "$boxed", "{", "return", "}".
* The highest attention weights are concentrated in layers 13, 17, and 22, suggesting these layers are crucial for processing the input sequence.
### Interpretation
This heatmap likely represents the attention mechanism within a transformer-based model, possibly used for question answering or code generation. The model appears to initially focus on the input context ("A and B", "8", "13", "[in", "boxed", "]"), then shifts its attention towards identifying the correct answer and the subsequent actions ("answer", "is", "$boxed", "{", "return", "}").
The evolution of attention weights suggests a hierarchical processing of information. The initial layers extract basic features, while deeper layers combine these features to make more informed decisions. The peaks in attention weights indicate the parts of the input sequence that are most relevant for the model's task.
The fact that attention is focused on "$boxed", "{", and "return" in the later layers suggests the model is preparing to execute or return a result, potentially within a programming context. The presence of these tokens indicates the model is not just identifying the answer but also considering the actions needed to present or utilize it.