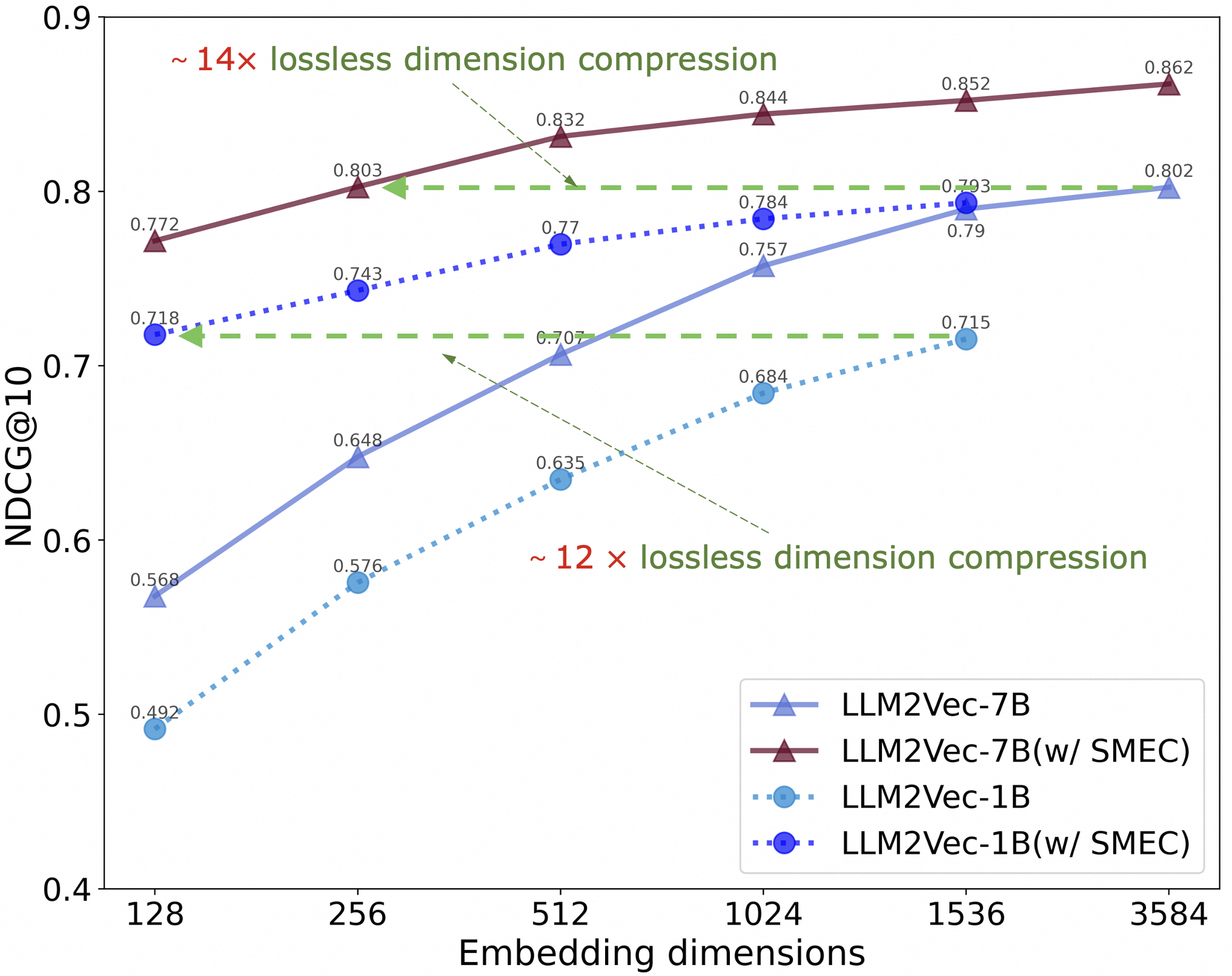
## Line Chart: NDCG@10 Performance vs. Embedding Dimensions
### Overview
The chart compares the performance of four language model variants (LLM2Vec-7B, LLM2Vec-7B with SMEC, LLM2Vec-1B, and LLM2Vec-1B with SMEC) across different embedding dimensions (128 to 3584). Performance is measured as NDCG@10, a metric for ranking quality, plotted against embedding dimensions. The chart includes annotations for lossless dimension compression ratios (~12x and ~14x) and visualizes trends in model efficiency and effectiveness.
### Components/Axes
- **X-axis**: "Embedding dimensions" (logarithmic scale: 128, 256, 512, 1024, 1536, 3584).
- **Y-axis**: "NDCG@10" (normalized Discounted Cumulative Gain at 10 results, range: 0.4–0.9).
- **Legend**: Located in the bottom-right corner, mapping colors/markers to model variants:
- **Blue line with triangles**: LLM2Vec-7B
- **Maroon line with triangles**: LLM2Vec-7B(w/ SMEC)
- **Dashed cyan line with circles**: LLM2Vec-1B
- **Dotted blue line with squares**: LLM2Vec-1B(w/ SMEC)
- **Annotations**:
- Green dashed lines labeled "~12x lossless dimension compression" and "~14x lossless dimension compression."
- Arrows pointing to specific data points (e.g., 0.832 at 512 dimensions for LLM2Vec-7B(w/ SMEC)).
### Detailed Analysis
1. **LLM2Vec-7B(w/ SMEC)** (Maroon line):
- Starts at **0.772** (128 dimensions) and increases steadily to **0.862** (3584 dimensions).
- Shows the highest NDCG@10 across all dimensions, with a ~14x lossless compression annotation at 512 dimensions.
2. **LLM2Vec-7B** (Blue line):
- Begins at **0.718** (128 dimensions) and rises to **0.802** (3584 dimensions).
- Outperforms LLM2Vec-1B variants but lags behind its SMEC-enhanced counterpart.
3. **LLM2Vec-1B(w/ SMEC)** (Dotted blue line):
- Starts at **0.492** (128 dimensions) and improves to **0.802** (3584 dimensions).
- Demonstrates the largest relative gain (~12x compression) at 512 dimensions.
4. **LLM2Vec-1B** (Dashed cyan line):
- Begins at **0.568** (128 dimensions) and reaches **0.715** (3584 dimensions).
- Shows minimal improvement compared to its SMEC-enhanced version.
### Key Observations
- **SMEC Enhancement**: All SMEC variants (7B and 1B) outperform their base models, with the 1B SMEC variant showing the most dramatic improvement (~12x compression).
- **Model Size Impact**: Larger models (7B) consistently achieve higher NDCG@10 than smaller models (1B), even without SMEC.
- **Diminishing Returns**: Performance gains plateau as embedding dimensions increase, particularly beyond 1024 dimensions.
### Interpretation
The data highlights the interplay between model size, embedding dimensions, and efficiency techniques like SMEC. While larger models (7B) inherently perform better, SMEC significantly boosts the efficiency of smaller models (1B), enabling them to approach the performance of larger models with reduced computational overhead. The ~12x and ~14x compression annotations suggest that SMEC allows for substantial dimensionality reduction without sacrificing ranking quality. This implies that SMEC is a critical optimization for deploying resource-constrained models in real-world applications.