\n
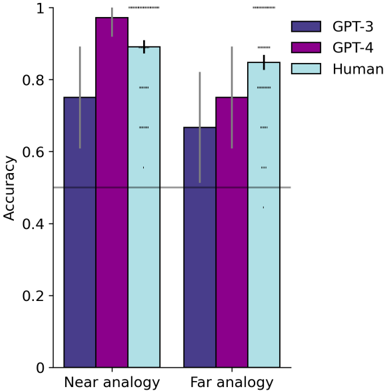
## Bar Chart: Accuracy of Analogy Completion by Model and Human
### Overview
This bar chart compares the accuracy of analogy completion tasks performed by three entities: GPT-3, GPT-4, and Humans. The comparison is made for two types of analogies: "Near analogy" and "Far analogy". Each bar represents the average accuracy, and error bars indicate the variability around that average.
### Components/Axes
* **X-axis:** Analogy Type (Near analogy, Far analogy)
* **Y-axis:** Accuracy (Scale from 0 to 1)
* **Legend:**
* GPT-3 (Dark Purple)
* GPT-4 (Purple)
* Human (Light Blue)
### Detailed Analysis
The chart consists of six bars, two for each analogy type, representing the accuracy of each entity. Error bars are present on top of each bar.
**Near Analogy:**
* **GPT-3:** The bar is approximately 0.78 in height. The error bar extends from approximately 0.72 to 0.84.
* **GPT-4:** The bar is approximately 0.93 in height. The error bar extends from approximately 0.88 to 0.98.
* **Human:** The bar is approximately 0.91 in height. The error bar extends from approximately 0.85 to 0.97.
**Far Analogy:**
* **GPT-3:** The bar is approximately 0.68 in height. The error bar extends from approximately 0.62 to 0.74.
* **GPT-4:** The bar is approximately 0.77 in height. The error bar extends from approximately 0.71 to 0.83.
* **Human:** The bar is approximately 0.86 in height. The error bar extends from approximately 0.80 to 0.92.
### Key Observations
* GPT-4 consistently outperforms GPT-3 in both Near and Far analogy tasks.
* Humans achieve the highest accuracy in both analogy types, though the difference between Humans and GPT-4 is smaller for Far analogies.
* Accuracy decreases for all entities when moving from Near to Far analogies.
* The error bars suggest that the variability in human performance is relatively low compared to the models.
### Interpretation
The data suggests that GPT-4 demonstrates a significant improvement over GPT-3 in its ability to understand and complete analogies. While GPT-4 approaches human-level performance, humans still exhibit the highest accuracy, particularly in the more challenging "Far analogy" tasks. The decrease in accuracy from Near to Far analogies indicates that the difficulty of the task impacts performance for all entities. The relatively small error bars for humans suggest a more consistent understanding of analogies compared to the models, which exhibit greater variability. This could be due to the models' reliance on statistical patterns rather than genuine understanding of the underlying relationships. The chart highlights the progress made in language model capabilities but also underscores the gap that remains between artificial and human intelligence in reasoning and analogical thinking.