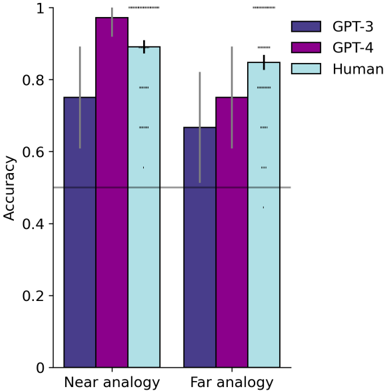
\n
## Bar Chart: Accuracy Comparison on Near vs. Far Analogies
### Overview
The image is a grouped bar chart comparing the accuracy of three entities—GPT-3, GPT-4, and Humans—on two types of tasks: "Near analogy" and "Far analogy." The chart includes error bars for each data point and a horizontal reference line at the 0.5 accuracy level.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **Y-Axis:**
* **Label:** "Accuracy"
* **Scale:** Linear, ranging from 0 to 1, with major tick marks at 0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis:**
* **Categories:** Two primary categories are displayed: "Near analogy" (left group) and "Far analogy" (right group).
* **Legend:**
* **Location:** Top-right corner of the chart area.
* **Entries:**
* **GPT-3:** Represented by a dark purple bar.
* **GPT-4:** Represented by a magenta bar.
* **Human:** Represented by a light blue bar.
* **Additional Elements:**
* **Error Bars:** Each bar has a vertical black line extending above and below the top of the bar, indicating variability or confidence intervals.
* **Reference Line:** A solid horizontal gray line is drawn across the chart at the `y = 0.5` mark.
### Detailed Analysis
**1. Near Analogy Task (Left Group):**
* **GPT-3 (Dark Purple):** The bar height is approximately **0.75**. The error bar extends from roughly 0.60 to 0.90.
* **GPT-4 (Magenta):** This is the tallest bar in the chart, with a height very close to **1.0** (approximately 0.98). Its error bar is relatively small, spanning from about 0.95 to 1.0.
* **Human (Light Blue):** The bar height is approximately **0.90**. The error bar extends from about 0.80 to 1.0.
**2. Far Analogy Task (Right Group):**
* **GPT-3 (Dark Purple):** The bar height is approximately **0.65**. The error bar is substantial, extending from roughly 0.50 to 0.80.
* **GPT-4 (Magenta):** The bar height is approximately **0.75**. The error bar spans from about 0.60 to 0.90.
* **Human (Light Blue):** The bar height is approximately **0.85**. The error bar extends from about 0.70 to 1.0.
**Trend Verification:**
* **GPT-3:** Performance drops from ~0.75 (Near) to ~0.65 (Far).
* **GPT-4:** Performance drops significantly from ~0.98 (Near) to ~0.75 (Far).
* **Human:** Performance shows a smaller decline from ~0.90 (Near) to ~0.85 (Far).
### Key Observations
1. **Performance Hierarchy (Near):** GPT-4 > Human > GPT-3. GPT-4 achieves near-perfect accuracy on near analogies.
2. **Performance Hierarchy (Far):** Human > GPT-4 > GPT-3. Humans outperform both models on far analogies.
3. **Largest Performance Drop:** GPT-4 exhibits the most dramatic decrease in accuracy (~23 percentage points) when moving from near to far analogies.
4. **Most Consistent Performance:** Humans show the smallest decline in accuracy between the two tasks (~5 percentage points).
5. **Error Bar Patterns:** Error bars are generally larger for the "Far analogy" task across all entities, suggesting greater variability or uncertainty in performance on more distant analogies.
6. **Reference Line:** All data points are above the 0.5 (chance) line, indicating all entities perform better than random guessing on both tasks.
### Interpretation
The data suggests a clear distinction in how different systems handle analogical reasoning based on the "distance" of the analogy.
* **GPT-4's Specialization:** GPT-4 demonstrates exceptional, near-human-level mastery of **near analogies**, which likely involve surface-level or closely related conceptual mappings. Its performance drop on far analogies indicates a potential limitation in abstracting or transferring knowledge to more distant domains.
* **Human Robustness:** Humans show strong and relatively stable performance across both task types. Their slight edge on far analogies suggests a superior ability for abstract reasoning and flexible knowledge application, which are hallmarks of human cognition.
* **GPT-3's Baseline:** GPT-3 serves as a baseline, showing competent but inferior performance to both GPT-4 and humans on both tasks, with a notable struggle on far analogies.
* **Implication for AI Development:** The chart highlights that while advanced models like GPT-4 can achieve superhuman performance on specific, well-defined tasks (near analogies), bridging the gap to human-like robustness and flexibility in more abstract reasoning (far analogies) remains a challenge. The larger error bars on far analogies for all groups also indicate this is a more difficult and variable problem space.