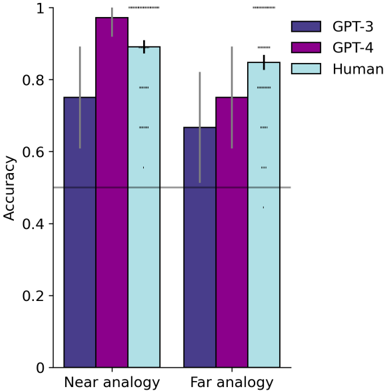
## Bar Chart: Model Accuracy Comparison in Analogy Tasks
### Overview
The chart compares the accuracy of three entities (GPT-3, GPT-4, and Humans) across two analogy task types: "Near analogy" and "Far analogy". Accuracy is measured on a 0-1 scale, with error bars indicating variability.
### Components/Axes
- **X-axis**: Task type ("Near analogy", "Far analogy")
- **Y-axis**: Accuracy (0-1 scale, increments of 0.2)
- **Legend**:
- Purple (#4B0082): GPT-3
- Pink (#FF69B4): GPT-4
- Light blue (#ADD8E6): Human
- **Error bars**: Vertical lines with caps, positioned above each bar
### Detailed Analysis
1. **Near analogy**:
- GPT-3: 0.75 (±0.12)
- GPT-4: 0.98 (±0.05)
- Human: 0.90 (±0.08)
2. **Far analogy**:
- GPT-3: 0.67 (±0.15)
- GPT-4: 0.76 (±0.10)
- Human: 0.85 (±0.07)
### Key Observations
- GPT-4 consistently outperforms GPT-3 in both task types (Δ=0.23 in Near, Δ=0.09 in Far)
- Humans achieve highest accuracy in Far analogy (0.85 vs GPT-4's 0.76)
- Error margins are largest for GPT-3 in Far analogy (±0.15)
- All entities show higher accuracy in Near analogy tasks
### Interpretation
The data demonstrates:
1. **Model progression**: GPT-4's superior performance over GPT-3 suggests architectural improvements
2. **Human advantage**: Humans maintain an edge in complex (Far) analogy tasks despite model advancements
3. **Task sensitivity**: Both models show significant performance drops in Far analogy (GPT-3: 0.75→0.67, GPT-4: 0.98→0.76)
4. **Error patterns**: GPT-3 exhibits greater variability in complex tasks, while GPT-4 maintains tighter confidence intervals
The chart reveals persistent challenges in analogical reasoning for AI systems, particularly in tasks requiring abstract pattern recognition. While GPT-4 closes the gap with humans in simple analogies, the performance disparity widens in complex scenarios, highlighting fundamental differences in cognitive processing between biological and artificial systems.